在实际应用中进行主题建模 —— 利用 LangChain 把从临时性 Jupyter 笔记本转变为实际生产的模块化服务 [译]
Mariya Mansurova
![在实际应用中进行主题建模 —— 利用 LangChain 把从临时性 Jupyter 笔记本转变为实际生产的模块化服务 [译]](/images/rag/topic-modelling-in-production/1_zrrzdFgAnm7YAyIYtINhoA.webp)
利用 LangChain 把从临时性 Jupyter 笔记本转变为实际生产的模块化服务
在先前的文章中,我们探讨了如何利用 ChatGPT 进行主题建模,并取得了显著成效。我们的任务是分析酒店连锁的客户评价,找出其中的主要议题。
在之前的尝试中,我们运用了标准的 ChatGPT 完成 API 并亲自编写了原始提示。这种方式对于一些特定的分析研究非常有效。
但如果你的团队正在积极地关注和分析客户评价,采取一些自动化措施是非常有益的。优秀的自动化不仅可以帮助你构建一个独立的流程,还能提供更便捷的体验(即便是不懂大语言模型和编程的团队成员也能轻松获取数据),同时还更加节省成本(你只需一次性向大语言模型发送所有文本并支付费用)。
如果我们要构建一个可持续发展的、准备投入生产的服务,那么利用现有的框架来减少编写辅助代码的工作量,并实现更模块化的解决方案是非常值得的(例如,我们可以轻松地从一个大语言模型切换到另一个)。
在本文中,我将介绍一个非常流行的大语言模型应用框架 — LangChain。我们还将详细了解如何评估模型的性能,这对于商业应用来说至关重要。
生产过程中的细节
改进初始方法
首先,让我们回顾一下之前的临时性主题建模方法。
步骤 1: 获取具有代表性的样本。
我们需要确定将用于标注的主题列表。最直接的方法是提交所有评论,并请大语言模型确定评论中提到的 20-30 个主题。不过,由于这些内容超出了上下文的限制,我们无法这样做。我们可以采用 map-reduce(映射 - 简化)方法,但这可能成本较高。因此,我们选择确定一个有代表性的样本。
为此,我们创建了一个 BERTopic 主题模型,并找出了每个主题中最具代表性的评论。
步骤 2: 确定用于标注的主题列表。
接下来的步骤是将所有精选文本提交给 ChatGPT,并请求其确定这些评论中提到的主题列表。然后,我们可以利用这些主题进行后续的标注工作。
步骤 3: 分批进行主题标注。
最后一步是最简单的 — 我们可以将客户评论分批提交,确保它们适应上下文大小,并请求大语言模型针对每个客户评论返回相应的主题。
通过这三个步骤,我们能够确定文本中相关的主题列表并进行分类。
这种方法非常适合一次性的研究。然而,要打造一个优秀的、适合生产环境的解决方案,我们还需要考虑一些其他因素。
从临时解决方案到生产实施
我们来探讨如何对我们最初的临时方案进行改进。
- 在先前的方案中,我们使用了一个固定的主题列表。然而,在实际应用中,随着时间的推移可能会出现新的主题,比如推出新功能时。因此,我们需要建立一个反馈机制,以便更新我们所使用的主题列表。最简单的方法是,收集那些未被分配主题的评论,并定期对它们进行主题分析 (topic modelling)。
- 在进行一次性研究时,我们可以手动检查主题分配的准确性。但对于在生产环境中运行的流程,我们需要考虑如何持续地评估其效果。
- 当我们构建客户评论分析流程时,应当考虑更多可能的应用场景,并存储可能需要的相关信息。举个例子,存储客户评论的翻译版本将大有裨益,这样我们的同事就无需频繁使用谷歌翻译。此外,评论的情感倾向和其他特点(比如评论中提到的产品)对于分析和筛选也非常重要。
- 目前,大语言模型 (LLM) 领域正在迅速进步,变化不断。因此,考虑采用一种模块化的方法是明智的,这样我们可以在不需要重构整个服务的情况下,快速试验和应用新的方法。
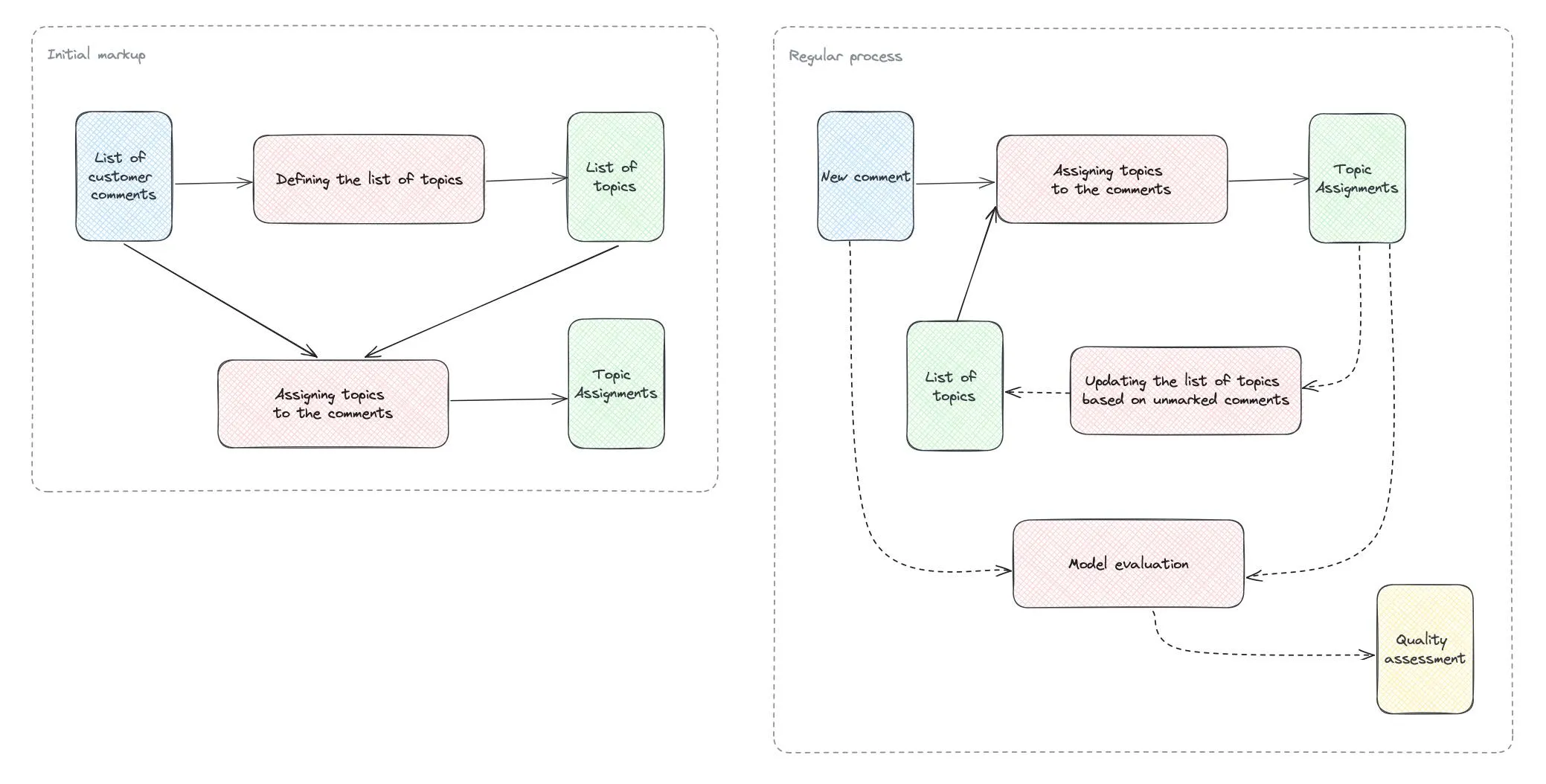
我们对如何改进主题建模服务有诸多想法。但现在,让我们集中注意力在主要部分:采用模块化方法而非依赖 API 调用,并进行有效评估。LangChain 框架将在这两方面为我们提供帮助,让我们深入了解一下。
LangChain 概述
LangChain 是一个专门用于创建基于大语言模型 (Language Models) 的应用程序的框架。它包含了一系列主要的组件,简要说明如下:
- Schema(结构):包括了文档、聊天信息和文本等基础类别。
- Models(模型):LangChain 支持多种大语言模型、聊天模型和文本嵌入模型,让你在应用中轻松切换和使用。它支持的模型包括了知名的 ChatGPT、Anthropic 和 Llama。
- Prompts(提示):这是一个辅助处理提示的工具,包括提示模板、输出解析和针对少样本提示的示例选择功能。
- Chains(链条):正如其名,它是 LangChain 的核心。Chains 助你构建一系列将要执行的操作块,特别适用于构建复杂的应用程序。
- Indexes(索引):涵盖文档加载、文本分割、向量存储和检索等功能。这一模块主要用于帮助大语言模型处理文档,尤其适用于问答系统的构建。但在我们今天的示例中,不会过多地使用此功能。
- LangChain 还提供了一整套内存管理方法,主要用于聊天机器人场景中的内存限制和管理。
- 最新且极具影响力的功能之一是智能体 (agents)。如果你经常使用 ChatGPT,那你可能会对插件功能不陌生。智能体功能就是基于类似的理念,允许大语言模型结合一系列定制或预定义的工具(比如 Google 搜索或维基百科),在回答问题时加以利用。在这种模式下,大语言模型扮演着推理智能体的角色,决定如何实现目标,并在得到最终答案时提供反馈。这个功能非常有趣,值得深入探讨。
因此,LangChain 能帮助我们构建模块化的应用程序,并在不同组件之间灵活切换,比如从 ChatGPT 切换到 Anthropic,或者从 CSV 数据输入切换到 Snowflake 数据库。LangChain 提供了超过190 种集成,极大地节省了开发时间。
另外,我们还可以利用已有的链条解决方案来处理特定用例,而无需从头开始。
手动调用 ChatGPT API 时,我们通常需要编写大量的 Python 代码来实现功能。这在处理小型、简单的任务时尚可应对,但在构建更复杂的系统时,代码管理可能变得复杂难以维护。LangChain 正是在这种情况下发挥作用,它能帮助去除冗余代码,创建更易维护的模块化代码结构。
然而,LangChain 也有它自己的局限性:
- 该系统主要设计来支持 OpenAI 的模型,与自建的开源模型相比,可能在协同工作上不够流畅。
- 尽管方便快捷,但要理解 ChatGPT API 的内部机制以及其执行时间和方式并非易事。您可以切换到调试模式,但这需要您指定并仔细查看完整日志,以便更好地了解情况。
- 虽然官方文档写得很好,但我有时仍会难以找到问题的答案。网络上关于这个主题的其他教程和资源不多,通常在谷歌搜索中只能看到官方的页面。
- Langchain 库正在迅速发展,团队持续推出新功能。因此,这个库还不够成熟,您可能需要更换当前正在使用的某些功能。比如,
SequentialChain类现在已被视为过时,未来可能会被弃用,因为他们推出了新的 LCEL 功能 — 我们稍后将对此进行更详尽的讨论。
我们已经大致了解了 LangChain 的功能,但要真正掌握它,还需要实践。现在,让我们开始实际应用 LangChain。
优化主题分配流程
我们将重构主题分配流程,因为这是我们日常工作中最常进行的操作,它能帮助我们更好地理解 LangChain 的实际应用。
首先,我们需要安装这个软件包。
!pip install --upgrade langchain
加载文档
为了处理客户评论,我们首先需要导入这些数据。我们可以使用 文档加载器 来完成这一步。在我们的例子中,客户评论以一系列 .txt 文件的形式存储在一个文件夹中,但您也可以从第三方工具中轻松导入文档。例如,这里有一个与 Snowflake 的 集成方案。
我们将使用 DirectoryLoader 来加载文件夹中的所有文件,因为我们有来自不同酒店的独立文件。对每个文件,我们将指定 TextLoader 作为其加载器(默认情况下会使用针对非结构化文档的加载器)。我们的文件采用 ISO-8859–1 编码,因此默认的调用会产生错误。不过,LangChain 能够自动检测并适应所用的编码。有了这样的配置,一切都运行得很顺利。
from langchain.document_loaders import TextLoader, DirectoryLoadertext_loader_kwargs={'autodetect_encoding': True}loader = DirectoryLoader('./hotels/london', show_progress=True,loader_cls=TextLoader, loader_kwargs=text_loader_kwargs)docs = loader.load()len(docs)82
文档的分割处理
目前,我们需要对文档进行分割。每个文件包含了由 \n 分隔的顾客评论序列。考虑到我们的案例相对简单直接,我们选择使用基础的 CharacterTextSplitter 按字符进行文档分割。但在处理实际文档(例如完整的长篇文本,而非单独的短评)时,更推荐使用 递归字符分割方法,因为它能更加智能地将文档分成多个部分。
然而,LangChain 在处理模糊文本分割方面表现更佳。因此,我对其进行了一些调整,使其符合我的需求。
其工作原理如下:
- 你需要设置
chunk_size(块大小)和chunk_overlap(块重叠),系统会尽量减少分割次数,确保每个块的大小不超过chunk_size。如果无法生成足够小的块,系统会在 Jupyter Notebook 的输出中显示一条信息。 - 如果设定的
chunk_size过大,可能无法将所有评论完全分开。 - 如果
chunk_size设置过小,则每条评论都会在输出中生成一条打印语句,可能导致 Notebook 重新加载。遗憾的是,我没有找到关闭此功能的参数。
为解决这个问题,我将 length_function 设置为一个与 chunk_size 相等的常数值。这样,我就实现了标准的字符分割。LangChain 在灵活性方面表现出色,尽管需要一些技巧性的调整。
from langchain.text_splitter import CharacterTextSplittertext_splitter = CharacterTextSplitter(separator = "\n",chunk_size = 1,chunk_overlap = 0,length_function = lambda x: 1, # usually len is usedis_separator_regex = False)split_docs = text_splitter.split_documents(docs)len(split_docs)12890
此外,我们还将文档 ID 加入到元数据中,以便后续使用。
for i in range(len(split_docs)):split_docs[i].metadata['id'] = i
使用文档的一个优势是,我们现在可以自动获取数据源,并根据数据源进行数据过滤。例如,我们可以筛选出仅与 Travelodge Hotel 相关的评论。
list(filter(lambda x: 'travelodge' in x.metadata['source'],split_docs))
接下来,我们需要一个模型。如我们之前在 LangChain 中讨论的那样,存在大语言模型(LLMs)和聊天模型(Chat Models)。它们的主要区别在于,大语言模型处理文本输入并返回文本输出,而聊天模型则更适合对话场景,能够处理一系列的信息输入。在我们的案例中,我们选择使用 OpenAI 的聊天模型,因为我们希望同时处理系统消息。
from langchain.chat_models import ChatOpenAIchat = ChatOpenAI(temperature=0.0, model="gpt-3.5-turbo",openai_api_key = "your_key")
让我们继续重点内容 —— 编写提示 (prompt)。在 LangChain 中,存在一种被称为“提示模板” (Prompt Templates) 的设计,它允许我们通过变量来复用和自定义提示内容。这在实际应用中极为重要,因为应用程序的提示往往需要详细且复杂。提示模板作为一种高级抽象概念,能有效地帮助你管理代码。
由于我们要使用聊天模型 (Chat Model),因此我们需要用到 ChatPromptTemplate。
在深入了解提示前,先来看一个有用的功能 —— 输出解析器 (output parser)。这个工具可以帮助我们更好地构建提示内容。我们可以先定义期望的输出格式,然后创建一个输出解析器,并利用它来指导我们编写提示。
具体来说,我们希望能通过提示处理一系列客户评论,并最终得到以下参数的列表:
- id 用于识别各个文档,
- 一个预先定义的主题列表(我们将沿用之前的列表),
- 情感分析结果(负面、中性或正面)。
接下来,我们将定义输出解析器。鉴于我们需要构建一个较为复杂的 JSON 结构,我们选择使用 Pydantic Output Parser 而非常规的 Structured Output Parser。
我们需要定义一个继承自 BaseModel 的类,并详细指定所需字段的名称和描述,以便大语言模型 (LLM) 能理解我们期望的响应内容。
from langchain.output_parsers import PydanticOutputParserfrom langchain.pydantic_v1 import BaseModel, Fieldfrom typing import Listclass CustomerCommentData(BaseModel):doc_id: int = Field(description="doc_id from the input parameters")topics: List[str] = Field(description="List of the relevant topics \for the customer review. Please, include only topics from \the provided list.")sentiment: str = Field(description="sentiment of the comment (positive, neutral or negative")output_parser = PydanticOutputParser(pydantic_object=CustomerCommentData)
现在,我们可以利用这个解析器来设计我们提示的格式化结构。这样不仅能应用提示编写的最佳实践,还能节省编写提示的时间。
format_instructions = output_parser.get_format_instructions()print(format_instructions)

接着,我们开始编写我们的提示内容。我们收集了一批评论,并将它们格式化成所需的形式。随后,我们创建了一个包含多个变量(topics_descr_list、format_instructions 和 input_data)的提示信息。然后,我们制作了由固定的系统消息和提示信息组成的聊天提示。最后一步是将实际值填入这些聊天提示中。
from langchain.prompts import ChatPromptTemplatedocs_batch_data = []for rec in docs_batch:docs_batch_data.append({'id': rec.metadata['id'],'review': rec.page_content})topic_assignment_msg = '''Below is a list of customer reviews in JSON format with the following keys:1. doc_id - identifier for the review2. review - text of customer reviewPlease, analyse provided reviews and identify the main topics and sentiment. Include only topics from the provided below list.List of topics with descriptions (delimited with ":"):{topics_descr_list}Output format:{format_instructions}Customer reviews:
'''topic_assignment_template = ChatPromptTemplate.from_messages([("system", "You're a helpful assistant. Your task is to analyse hotel reviews."),("human", topic_assignment_msg)])topics_list = '\n'.join(map(lambda x: '%s: %s' % (x['topic_name'], x['topic_description']),topics))messages = topic_assignment_template.format_messages(topics_descr_list = topics_list,format_instructions = format_instructions,input_data = json.dumps(docs_batch_data))
现在,我们可以将这些经过格式化的消息发送给大语言模型 (LLM),并查看它的响应。
response = chat(messages)type(response.content)strprint(response.content)

我们收到了一个字符串格式的响应,但我们可以借助我们的解析器,将响应转换成 CustomerCommentData 类对象列表的形式。
response_dict = list(map(lambda x: output_parser.parse(x),response.content.split('\n')))response_dict

通过利用 LangChain 及其功能,我们已经构建了一个更加智能的解决方案。它不仅能批量处理评论,分配主题(这样可以节省成本),还能分析出评论的情感倾向。
增加更多逻辑
我们目前仅创建了简单的大语言模型(LLM)调用,未涉及复杂的关系和顺序安排。但在现实应用中,我们通常需要将任务分解为多个步骤。为此,我们可以运用“链”这一概念。在 LangChain 中,“链”是构建基础的关键元素。
LLMChain(LLM 链)
最基础的链类型是 LLMChain,它是大语言模型和提示信息的结合体。
通过这种方式,我们可以将原有逻辑重构为一个“链”。这样做虽然得到的结果与之前相同,但将所有元素集成于一个方法中,更为便捷。
from langchain.chains import LLMChaintopic_assignment_chain = LLMChain(llm=chat, prompt=topic_assignment_template)response = topic_assignment_chain.run(topics_descr_list = topics_list,format_instructions = format_instructions,input_data = json.dumps(docs_batch_data))
顺序链
LLMChain 相对基础,但链的真正优势在于构建更复杂的逻辑结构。让我们尝试打造一些更高级的应用。
顺序链的核心思想是将一个链的输出作为另一个链的输入。我们将使用 LangChain 表达语言(LCEL)来定义这些链。LCEL 是几个月前推出的新语言,它使得之前的 SimpleSequentialChain 或 SequentialChain 等方法变得过时。因此,花时间了解 LCEL 是非常有益的。
接下来,我们用 LCEL 重构之前的链条。
chain = topic_assignment_template | chatresponse = chain.invoke({'topics_descr_list': topics_list,'format_instructions': format_instructions,'input_data': json.dumps(docs_batch_data)})
如果你希望深入学习这一领域,我推荐你观看 LangChain 团队关于 LCEL 的教学视频。
应用顺序链
在某些场景下,进行多个顺序调用是非常有用的,这样可以将一个链的输出作为另一个链的输入。
在我们的例子中,我们首先将评论翻译成英语,接着进行话题建模和情感分析。
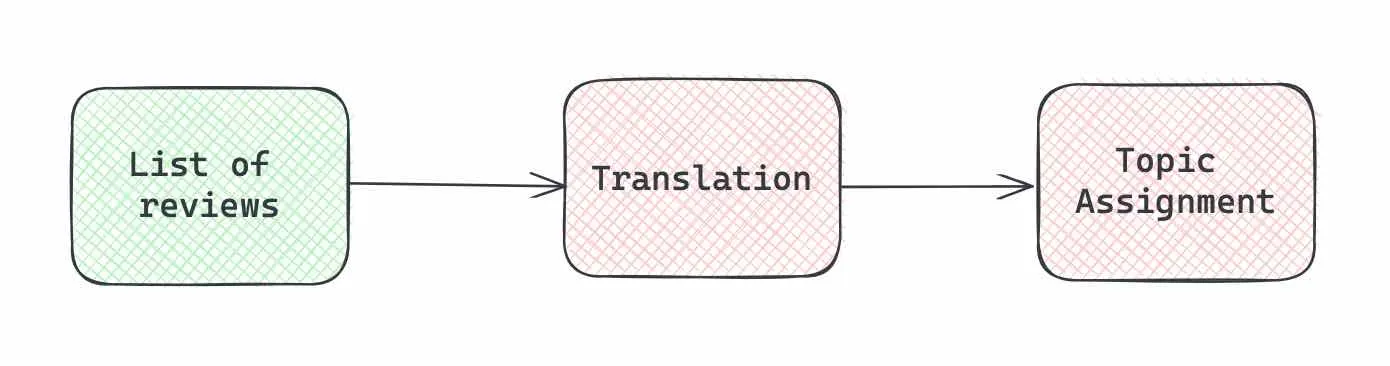
from langchain.schema import StrOutputParserfrom operator import itemgetter# translationtranslate_msg = '''Below is a list of customer reviews in JSON format with the following keys:1. doc_id - identifier for the review2. review - text of customer reviewPlease, translate review into English and return the same JSON back. Please, return in the output ONLY valid JSON without any other information.Customer reviews:
'''translate_template = ChatPromptTemplate.from_messages([("system", "You're an API, so you return only valid JSON without any comments."),("human", translate_msg)])# topic assignment & sentiment analysistopic_assignment_msg = '''Below is a list of customer reviews in JSON format with the following keys:1. doc_id - identifier for the review2. review - text of customer reviewPlease, analyse provided reviews and identify the main topics and sentiment. Include only topics from the provided below list.List of topics with descriptions (delimited with ":"):{topics_descr_list}Output format:{format_instructions}Customer reviews:
'''topic_assignment_template = ChatPromptTemplate.from_messages([("system", "You're a helpful assistant. Your task is to analyse hotel reviews."),("human", topic_assignment_msg)])# defining chainstranslate_chain = translate_template | chat | StrOutputParser()topic_assignment_chain = {'topics_descr_list': itemgetter('topics_descr_list'),'translated_data': translate_chain,'format_instructions': itemgetter('format_instructions')}| topic_assignment_template | chat# executionresponse = topic_assignment_chain.invoke({'topics_descr_list': topics_list,'format_instructions': format_instructions,'input_data': json.dumps(docs_batch_data)})
我们首先为翻译和话题分配定义了提示模板。接着,我们建立了翻译链。新引入的是 StrOutputParser(),其作用是将响应对象转化为文本字符串,这一过程相对简单直接。
随后,我们构建了完整的链条,明确了输入参数、提示模板和 LLM 的使用。对于输入参数,我们从 translate_chain 得到的 translated_data 作为输入,同时使用 itemgetter 函数从调用输入中获取其他所需参数。
然而,在我们的案例中,将所有功能合并为一个链条可能并不是最方便的选择,因为我们也希望保存第一个链条的输出,以便保留翻译后的内容。
在使用链条的过程中,情况可能会变得较为复杂,因此我们可能需要一定的调试能力。对于调试,有两种方法。一种是在本地开启调试功能。
import langchainlangchain.debug = True
另一种方法是利用 LangChain 平台的 LangSmith 工具。但请注意,LangSmith 目前仍处于测试阶段,因此可能需要等待一段时间才能获得访问权限。
路由功能解析
在应用场景中最复杂的一种情形就是使用不同的提示信息针对不同的用途进行路由。例如,在处理客户评论时,我们可以根据评论的情感倾向,采用不同的参数保存方法:
- 如果评论是负面的,我们会记录客户提及的各种问题。
- 如果是正面的,我们则提取并记录评论中的亮点。
使用路由功能意味着我们需要逐条处理评论,而非之前的批量处理方式。
因此,我们的处理流程在宏观上可以这样展示:
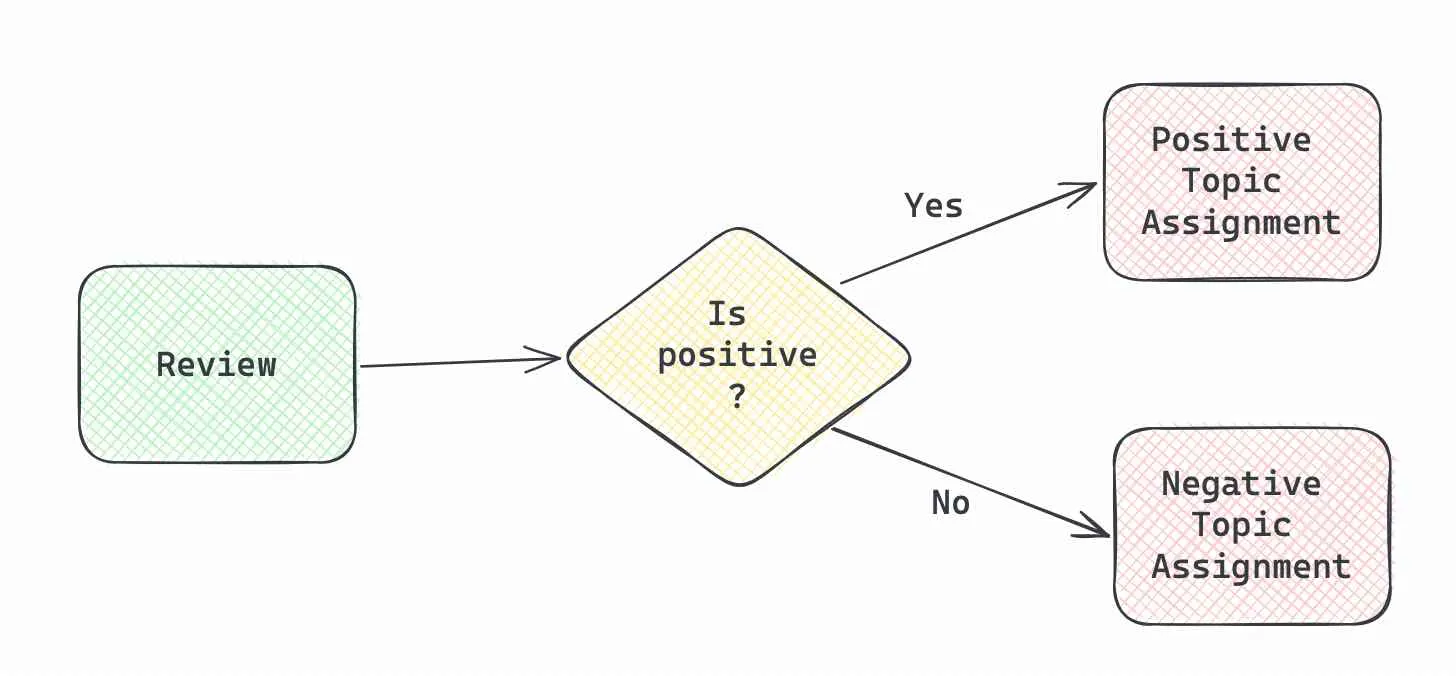
首先,我们需要设置一个主处理流程来判断评论的情感倾向。这个流程包括输入提示、大语言模型 (LLM) 和我们熟悉的StrOutputParser()文本输出解析器。
sentiment_msg = '''Given the customer comment below please classify whether it's negative. If it's negative, return "negative", otherwise return "positive".Do not respond with more than one word.Customer comment:
'''sentiment_template = ChatPromptTemplate.from_messages([("system", "You're an assistant. Your task is to markup sentiment for hotel reviews."),("human", sentiment_msg)])sentiment_chain = sentiment_template | chat | StrOutputParser()
针对积极评论,我们会引导模型提取评论中的优点;对于消极评论,则是提取问题所在。因此,我们需要设置两套不同的处理流程。我们将继续使用之前的 Pydantic 输出解析器,来确保输出格式符合预期,并生成相应的指令。
为了区分不同情绪的评论,我们在一般提示消息的基础上加入了partial_variables,来指定正面和负面评论的不同处理指令。
from langchain.prompts import PromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplate, SystemMessagePromptTemplate# defining structure for positive and negative casesclass PositiveCustomerCommentData(BaseModel):topics: List[str] = Field(description="List of the relevant topics for the customer review. Please, include only topics from the provided list.")advantages: List[str] = Field(description = "List the good points from that customer mentioned")sentiment: str = Field(description="sentiment of the comment (positive, neutral or negative")class NegativeCustomerCommentData(BaseModel):topics: List[str] = Field(description="List of the relevant topics for the customer review. Please, include only topics from the provided list.")problems: List[str] = Field(description = "List the problems that customer mentioned.")sentiment: str = Field(description="sentiment of the comment (positive, neutral or negative")# defining output parsers and generating instructionspositive_output_parser = PydanticOutputParser(pydantic_object=PositiveCustomerCommentData)positive_format_instructions = positive_output_parser.get_format_instructions()negative_output_parser = PydanticOutputParser(pydantic_object=NegativeCustomerCommentData)negative_format_instructions = negative_output_parser.get_format_instructions()general_topic_assignment_msg = '''Below is a customer review delimited by ```.Please, analyse the provided review and identify the main topics and sentiment. Include only topics from the provided below list.List of topics with descriptions (delimited with ":"):{topics_descr_list}Output format:{format_instructions}Customer reviews:
'''# defining prompt templatespositive_topic_assignment_template = ChatPromptTemplate(messages=[SystemMessagePromptTemplate.from_template("You're a helpful assistant. Your task is to analyse hotel reviews."),HumanMessagePromptTemplate.from_template(general_topic_assignment_msg)],input_variables=["topics_descr_list", "input_data"],partial_variables={"format_instructions": positive_format_instructions} )negative_topic_assignment_template = ChatPromptTemplate(messages=[SystemMessagePromptTemplate.from_template("You're a helpful assistant. Your task is to analyse hotel reviews."),HumanMessagePromptTemplate.from_template(general_topic_assignment_msg)],input_variables=["topics_descr_list", "input_data"],partial_variables={"format_instructions": negative_format_instructions} )
现在,我们只需构建完整的处理流程。主要逻辑通过RunnableBranch运行分支和基于情感判断的条件来定义,这是由sentiment_chain情感链输出的结果决定的。
from langchain.schema.runnable import RunnableBranchbranch = RunnableBranch((lambda x: "negative" in x["sentiment"].lower(), negative_chain),positive_chain)full_route_chain = {"sentiment": sentiment_chain,"input_data": lambda x: x["input_data"],"topics_descr_list": lambda x: x["topics_descr_list"]} | branchfull_route_chain.invoke({'input_data': review,'topics_descr_list': topics_list})
以下是几个实际例子。这个流程运作得很好,能够根据评论的情感倾向返回不同的结果。

我们已经详细探讨了如何使用 LangChain 进行主题建模,并引入更复杂的逻辑。接下来,我们将讨论如何评估模型的性能。
性能评估
在生产环境中运行的任何系统的关键部分是进行评估。当我们在生产环境中运行大语言模型 (LLM) 时,确保其质量并持续监控是非常重要的。
在很多情况下,我们不仅可以依赖人工检查(即人们定期检查模型结果的小样本,以控制性能),还可以利用大语言模型本身来完成这项任务。例如,对于主题分配,我们可能使用了 ChatGPT 3.5,但为了评估,我们可以考虑使用更高级的 GPT 4(这与现实生活中你请资深同事审查代码的概念类似)。
Langchain 在这方面也能提供帮助,因为它提供了一系列评估工具:
- 字符串评估器 可以帮助我们评估模型的输出结果。这些工具种类繁多,从验证输出格式到基于提供的上下文或参考资料评估正确性,都有相应的方法。我们将在后面详细介绍这些评估方法。
- 另一类评估工具是比较评估器。如果你想比较两个不同大语言模型的性能(如A/B测试场景),这类工具会非常有用。今天我们不会深入探讨这些评估器的细节。
精确匹配
最简单的方法是将模型的输出与正确答案(例如专家或训练集给出的答案)进行直接比较。例如,我们可以用一个叫做 ExactMatchStringEvaluator 的工具来测试我们情感分析的效果。在这种情况下,我们不需要用到复杂的大语言模型。
from langchain.evaluation import ExactMatchStringEvaluatorevaluator = ExactMatchStringEvaluator(ignore_case=True,ignore_numbers=True,ignore_punctuation=True,)evaluator.evaluate_strings(prediction="positive.",reference="Positive")# {'score': 1}evaluator.evaluate_strings(prediction="negative",reference="Positive")# {'score': 0}
你还可以创建自己的评估工具 自定义字符串评估器 或者用 正则表达式 来匹配输出。
此外,还有工具可以检查输出的结构,比如验证输出是否是合法的 JSON,结构是否符合预期,并且与标准答案的差异有多大。更多信息可以在 这个文档 中找到。
嵌入距离评估
另一种实用的方法是看看 嵌入距离。这个方法会给出一个分数:分数越低代表答案越接近,效果越好。比如说,我们可以用所谓的欧几里得距离来评估找到的答案之间的差异。
from langchain.evaluation import load_evaluatorfrom langchain.evaluation import EmbeddingDistanceevaluator = load_evaluator("embedding_distance", distance_metric=EmbeddingDistance.EUCLIDEAN)evaluator.evaluate_strings(prediction="well designed rooms, clean, great location",reference="well designed rooms, clean, great location, good atmosphere"){'score': 0.20732719121627757}
我们得到了 0.2 的距离分数。但这种评估方式可能比较难以理解,因为你需要根据你的数据分布来设定一个合适的阈值。下面我们来看看基于大语言模型的评估方法,这种方法通常更容易理解。
标准评估
你可以用 LangChain 来根据一些标准或规则来评估大语言模型给出的答案。这里有一些预设的标准,你也可以自己定义标准。
from langchain.evaluation import Criterialist(Criteria)[<Criteria.CONCISENESS: 'conciseness'>,<Criteria.RELEVANCE: 'relevance'>,<Criteria.CORRECTNESS: 'correctness'>,<Criteria.COHERENCE: 'coherence'>,<Criteria.HARMFULNESS: 'harmfulness'>,<Criteria.MALICIOUSNESS: 'maliciousness'>,<Criteria.HELPFULNESS: 'helpfulness'>,<Criteria.CONTROVERSIALITY: 'controversiality'>,<Criteria.MISOGYNY: 'misogyny'>,<Criteria.CRIMINALITY: 'criminality'>,<Criteria.INSENSITIVITY: 'insensitivity'>,<Criteria.DEPTH: 'depth'>,<Criteria.CREATIVITY: 'creativity'>,<Criteria.DETAIL: 'detail'>]
有些标准不需要参考答案,比如 harmfulness 或 conciseness。但对于 correctness(正确性),你需要事先知道正确答案。我们来试试用它来评估我们的数据。
evaluator = load_evaluator("criteria", criteria="conciseness")eval_result = evaluator.evaluate_strings(prediction="well designed rooms, clean, great location",input="List the good points that customer mentioned",)
结果显示,我们得到了一个是否符合特定标准的答案,还有一系列的推理过程,帮助我们理解这个结果背后的逻辑,并且有可能根据这些来调整我们的问题。

如果你对这个过程感兴趣,可以开启 langchain.debug = True 功能,这样就可以看到发送给大语言模型的具体问题。

让我们来看看正确性这一标准。为了评估这一点,我们需要提供一个参考答案。
evaluator = load_evaluator("labeled_criteria", criteria="correctness")eval_result = evaluator.evaluate_strings(prediction="well designed rooms, clean, great location",input="List the good points that customer mentioned",reference="well designed rooms, clean, great location, good atmosphere",)

你甚至可以根据需要创建自己的评估标准,比如答案中是否提及了多个要点。
custom_criterion = {"multiple": "Does the output contain multiple points?"}evaluator = load_evaluator("criteria", criteria=custom_criterion)eval_result = evaluator.evaluate_strings(prediction="well designed rooms, clean, great location",input="List the good points that customer mentioned",)

评价打分
在标准化的评价方法中,我们通常只能得到一个简单的“是”或“不是”的回答。但有时,这样的答案并不足以全面评估情况。例如,在我们的案例中,预测结果包含了四个关键要点中的三个,这算是一个不错的成绩。但按照正确性来评估时,结果却是否定的。这样一来,“设计精良、干净、地理位置优越”的答案和“网络速度快”的答案在我们的评估标准中被视为等同,这显然无法帮助我们全面了解模型的表现。
还有一种类似的评分技术,它允许我们要求大语言模型(LLM)在输出时给出一个分数,这样可以获得更详细的评估结果。让我们来尝试一下。
from langchain.chat_models import ChatOpenAIaccuracy_criteria = {"accuracy": """Score 1: The answer doesn't mention any relevant points.Score 3: The answer mentions only few of relevant points but have major inaccuracies or includes several not relevant options.Score 5: The answer has moderate quantity of relevant options but might have inaccuracies or wrong points.Score 7: The answer aligns with the reference and shows most of relevant points and don't have completely wrong options mentioned.Score 10: The answer is completely accurate and aligns perfectly with the reference."""}evaluator = load_evaluator("labeled_score_string",criteria=accuracy_criteria,llm=ChatOpenAI(model="gpt-4"),)eval_result = evaluator.evaluate_strings(prediction="well designed rooms, clean, great location",input="""Below is a customer review delimited by ```. Provide the list the good points that customer mentioned in the customer review.Customer review:
虽然房间不大,但设计巧妙、干净、位置优越,氛围也很好。我愿意再次入住。虽然欧陆式早餐一般,但还可以接受。
""",reference="well designed rooms, clean, great location, good atmosphere")

我们得到了7分,这个评分似乎相当合理。让我们看一下实际的提示内容。

不过,我们在使用大语言模型给出的分数时还是应该持谨慎态度。需要记住的是,这并非一个严格的回归分析函数,所得的分数可能带有一定的主观性。
我们之前使用的是带有参考答案的评分模型。但在很多情况下,我们可能没有确切的参考答案,或者获取这些答案的成本可能很高。即使没有参考分数,我们也可以使用评分评估器让模型对答案进行评估。在这种情况下,使用 GPT-4 对结果进行评估可能会更加可靠。
accuracy_criteria = {"recall": "The asisstant's answer should include all mentioned in the question. If information is missing, score answer lower.","precision": "The assistant's answer should not have any points not present in the question."}evaluator = load_evaluator("score_string", criteria=accuracy_criteria,llm=ChatOpenAI(model="gpt-4"))eval_result = evaluator.evaluate_strings(prediction="well designed rooms, clean, great location",input="""Below is a customer review delimited by ```. Provide the list the good points that customer mentioned in the customer review.Customer review:
虽然房间不大,但设计巧妙、干净、位置优越,氛围也很好。我愿意再次入住。虽然欧陆式早餐一般,但还可以接受。
""")

我们得到的分数与之前非常接近。
我们探讨了多种方法来验证模型的输出结果,希望这些方法能帮助你有效地测试你的模型。
总结
在这篇文章中,我们探讨了在将大语言模型(LLM)应用于生产过程时需要考虑的一些细节。
- 我们讨论了如何利用 LangChain 框架使解决方案更加模块化,这样就可以轻松地进行迭代,采用新的方法(比如,从一个大语言模型切换到另一个)。此外,这样的框架还有助于简化代码的维护工作。
- 另一个重要话题是评估模型性能的不同工具。如果我们在生产环境中使用大语言模型,就需要进行持续的监控,以确保服务质量。因此,投入时间来构建基于大语言模型或人工参与的评估流程是非常有价值的。
感谢您阅读本文。希望这篇文章对您有所启发。如果您有任何后续问题或评论,请在评论区留言。
数据集简介
由 Ganesan, Kavita 和 Zhai, ChengXiang 在 2011 年发布的 OpinRank 评论数据集,现收录于 UCI 机器学习资源库。 (https://doi.org/10.24432/C5QW4W)
相关参考
本文内容参考了 DeepLearning.AI 与 LangChain 联合开设的课程“LangChain 应用于大语言模型(LLM)的开发”,提供了课程的详细信息和链接。