如果我们拥有世界上最好的产品工程组织,它会是什么样子?[译]
这是我在 2025 年 1 月 8 日的东京地区 Scrum Gathering 大会上所做主题演讲的文字记录。
“你怎么衡量生产力?”
那是 2023 年 9 月,我的 CEO 问了我这个问题。
“你怎么衡量生产力?”
那是 2023 年 9 月,我的 CEO 问了我这个问题,而我担任工程副总裁的时间还不到三个月。
“你怎么衡量生产力?”
那是 2023 年 9 月,我的 CEO 又问了同样的问题,我任职才不到三个月,而我没有答案。
于是我说了真话。
“我怎么衡量生产力?我并没有。软件工程的生产力是无法衡量的。”
这是真的!如何衡量生产力一直是个著名的话题,而业内最聪明的人都得出结论:这事儿没法做。Martin Fowler 在 2003 年写过一篇文章,名为 “无法衡量生产力”(CannotMeasureProductivity)。Kent Beck 和 Gergely Orosz 在 20 年后也再次讨论过这个问题。Kent Beck 总结道, “想要衡量开发者生产力?不可能。”
我最喜欢的讨论来自 Robert Austin,他写了《在组织中衡量与管理绩效》(Measuring and Managing Performance in Organizations)。他指出,基于测量的方法“只能带来相对有限的改进”,并会产生“严重的激励扭曲”。
我该怎么量化生产力?做不到。至少,在不制造大量功能紊乱的激励之前,没法做。
不过,我今天的演讲并不是为了讨论如何衡量生产力。而是要谈,当你作为工程副总裁,面对有人提出一个不可能——或者说危险——的需求时,你要怎么做。
[向右转] “你怎么衡量生产力?” [向左转] “我没有,我认为做不到。” [向右转] “你错了。我不信。”
我对这种简单粗暴的否定……应对得并不好。我对 CEO 说了一些平时不该对 CEO 说的话。
那是 2023 年 9 月,我任职还不到三个月,看上去我熬不到第四个月的月底了。
[停顿]
幸运的是,我的 CEO 其实是个相当通情达理的人。我们公司是全远程的,他邀请我下次到他所在的城市时去他家,当面聊聊这个问题。
这就给了我一个月的时间来冷静,思考我要说些什么。CEO 提出的要求“不可能”或至少“很危险”:去衡量生产力。既然我不能在不破坏工程文化的情况下满足他的需求,那我还能给他什么呢?
这才是我今天演讲的_真正_主题。

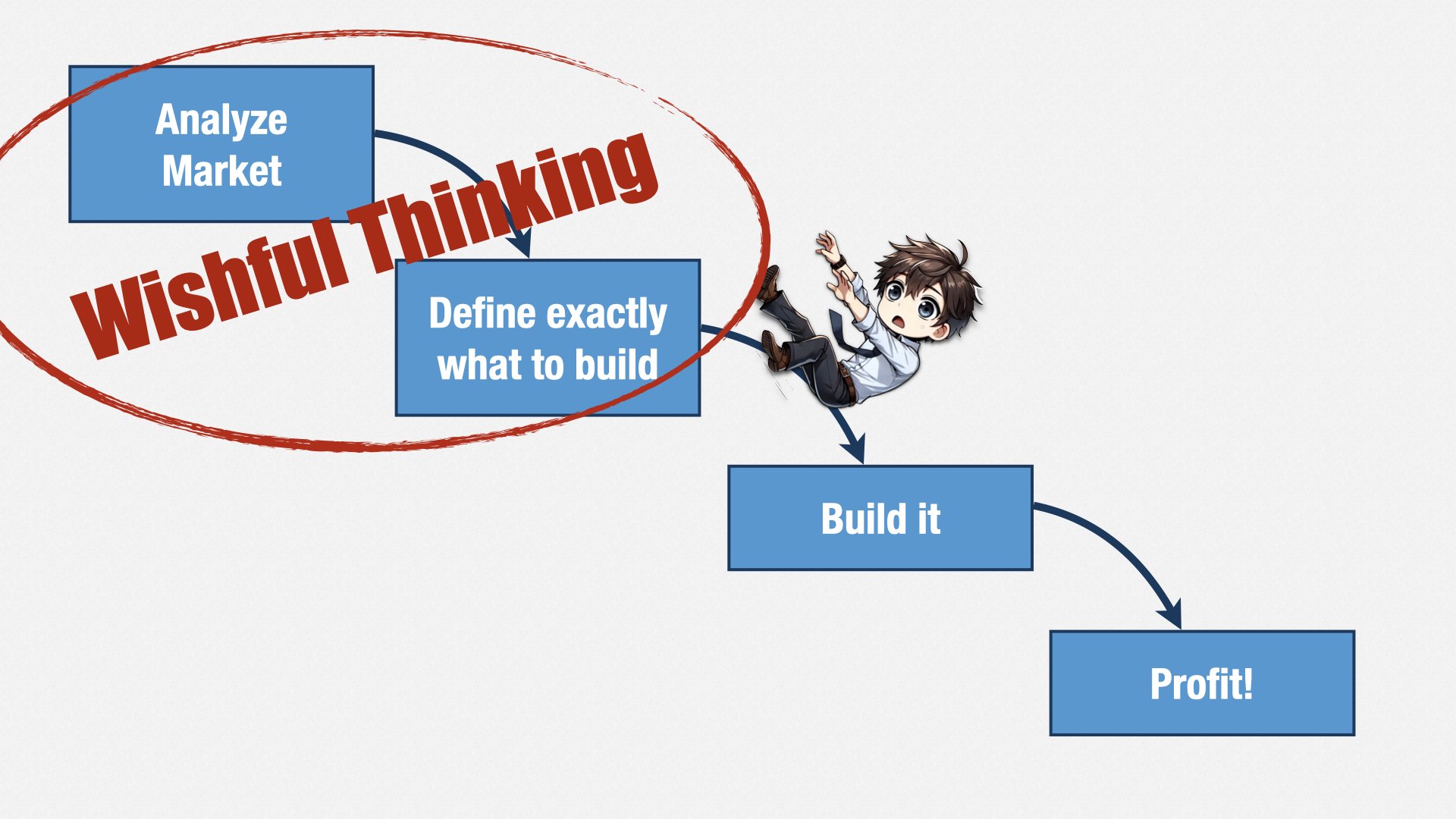
一个月后,我、CEO、首席产品官(CPO)和首席技术官(CTO)在他家见面。我说:“如果我们拥有全世界最好的产品工程组织,会是什么样子?”我当场带领他们做了一个练习,就在 CEO 家的餐桌上,用了大量索引卡片和便利贴……当然啦!

最后,我们得出了六大类。想象一下:如果我们是世界上最好的产品工程组织,会是什么样?

对于我们来说,这意味着以下六件事:
人员(People)。 我们要有行业内最优秀的人才,而且还要成为他们最想工作的地方。人才们会抢着来,离职的人也会在别处努力复制他们在这里的体验。
内部质量(Internal Quality)。 我们的软件修改和维护都应该非常容易,没有 bug、没有宕机。
可爱度(Lovability)。 我们的客户、用户以及内部使用者都应该爱上我们的产品。我们要擅长理解利益相关者的真实需求,并把我们的精力投入到最重要的地方。
可见度(Visibility)。 我们的内部利益相关者会信任我们的决策,不是因为我们完美无缺,而是因为我们会想方设法让他们参与并了解情况。
敏捷性(Agility)。 我们应当具备创业者的精神,行动敏捷,时刻警惕新的机会,并迅速转向加以利用。
盈利能力(Profitability)。 我们要成为一个能带动公司盈利和增长的引擎。我们要和内部利益相关者紧密合作,确保我们的产品准备好应对真实世界的销售、营销、内容、支持、合作伙伴、财务以及公司业务的各个方面。
我们现在是世界上最好的产品工程组织吗?不是。我们将来会不会成为?大概率也不会。
但我们并不需要真的成为世界第一。重点在于_不断_改进。这六大类就是我们想要改进的方向。
对你来说,这意味着什么?如果你和你自己的管理团队也做一次这样的练习,可能会得出不一样的答案。我并不是说我们定下的这六大类适合所有公司。
但这仍然是一个有意思的思考过程。我们是一家深受敏捷思维影响的组织。这六大类也许和你所在组织的一模一样,也可能不尽相同,但——“People、Internal Quality、Lovability、Visibility、Agility、Profitability”——这六件事都值得投资。我将介绍我们在每一类所做的事情。如果你是高层管理者,也许可以借鉴一些方法。
如果你_不是_高层管理者,或许可以把这些思路带给你们的管理层。只有当整个组织都真正支持敏捷时,敏捷才能成功。你可以把这些想法当做示例分享给管理层,看看如何支持你的敏捷团队。
让我们开始吧。
人员(People)

每家公司都想要业内最优秀的人才。但我们的公司规模相对较小,没法和 Google、Amazon、Apple 这样的 FAANG 巨头竞争。它们也在寻找最优秀的人才,并且拥有比我们更多的钱。

但我们依然可以找到行业内最优秀的人才。因为我们对“最优秀”的定义和他们不同。FAANG 公司看重的是名校背景、同类大厂的工作经历、能轻松搞定 Leetcode 的人。
可我们并不想要这样的人。

我们的组织结构是“倒置的”(inverted organization),也就是说,做具体工作的员工才做战术层决策,而不是由管理者来做(理论上是这样,当然还不完美)。所以我们需要拥有_同伴式领导_技能、擅长_团队协作_、愿意_承担责任_并_自行做决策_的员工。
同时我们是一家 XP 团队。我们把极限编程(Extreme Programming)视作开发软件的核心模式。而恰巧,XPer 非常重视团队协作、同伴式领导和主人翁意识。他们也热爱测试驱动开发、结对编程、持续集成以及演进式设计,往往是充满激情的资深开发者,而且他们非常渴望再次成为 XP 团队中的一员。
要知道,极限编程对大多数公司来说都太“极端”了,就像真正的敏捷或真正的 Scrum 对很多公司来说也很极端。你是否见过 Scrum 被当作微观管理(micromanagement)的借口?又或者某位高管让你“必须敏捷”,并且要求你提交一份未来一年团队要做些什么的详细计划?
换句话说,很少有公司真正运用 XP。有很多优秀的人才,希望能够应用 XP。我们可以从这些人中挑选最顶尖的人才。此外,我们还是全远程办公,在招聘地域上也很灵活。

我说我们是一家 XP 团队,但也不完全准确。公司的创始人受极限编程熏陶很深,曾经是真正的 XP 团队风格,但公司在快速发展时,曾丢掉了这股 XP 文化。我们有不少并不拥有 XP 思维模式的工程师。我们也需要让他们加入进来。
这属于组织文化变革,而变革组织文化并不轻松。我们的工程经理在其中发挥着关键作用。
为帮助他们,我们重新修订了晋升标准(Career Ladder)。这是一份说明在本公司需要做到什么才能晋升的文档。旧版的侧重点是掌握高级技术和构建复杂系统;新版则更加重视团队协作、同伴式领导、主人翁意识,以及 XP 工程技能(如 TDD、重构和简单设计)。

二维码:Career Ladder
它大概长这样,是个详细的电子表格,列出了工程组织中的各个职级,以及对应的技能要求。
例如,Associate Software Engineer(初级)是应届毕业生,只要有课堂层面(classroom-level)的编程技能即可。他们在其他团队成员的帮助下参与团队工作。
中级软件工程师(Software Engineer)则要求在无需具体指导的情况下对团队作出贡献,需要具备基本的沟通、领导、产品、实施、设计、运维等技能。
高级软件工程师(Senior Software Engineer)需具备上述技能的高级版;技术负责人(Technical Lead)需进一步带领和指导他人;等等。
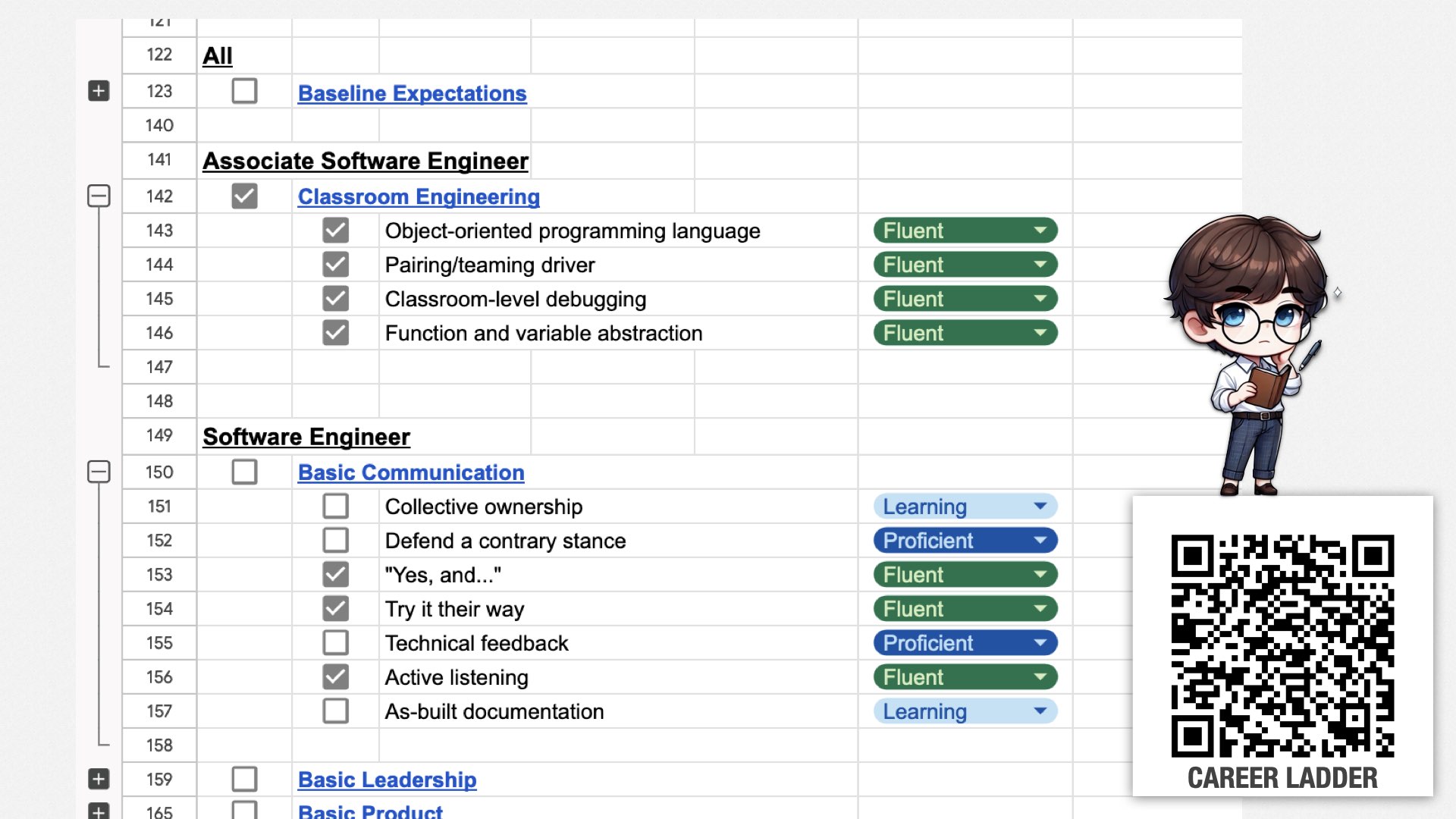
就像这样,每个层级定义了一系列具体技能。例如,Associate Software Engineer(初级)需要精通“Classroom Engineering”这个类别中的技能,包括使用面向对象语言、在结对中承担“driver”角色、基础的调试技巧,以及基础的函数与变量抽象。
中级软件工程师(Software Engineer)需要熟练掌握“Basic Communication”这一类技能,包括和团队成员协作、建设性地表达不同意见、在别人想法上再进一步完善(“Yes, and…”)、等等。
由于时间所限,我无法在这里深入讲解所有技能的细节。但你可以扫描二维码查看更详细的文章,其中也包括我们对这些技能的文档说明。
今天,我想重点介绍其中一些我认为尤其重要的技能。
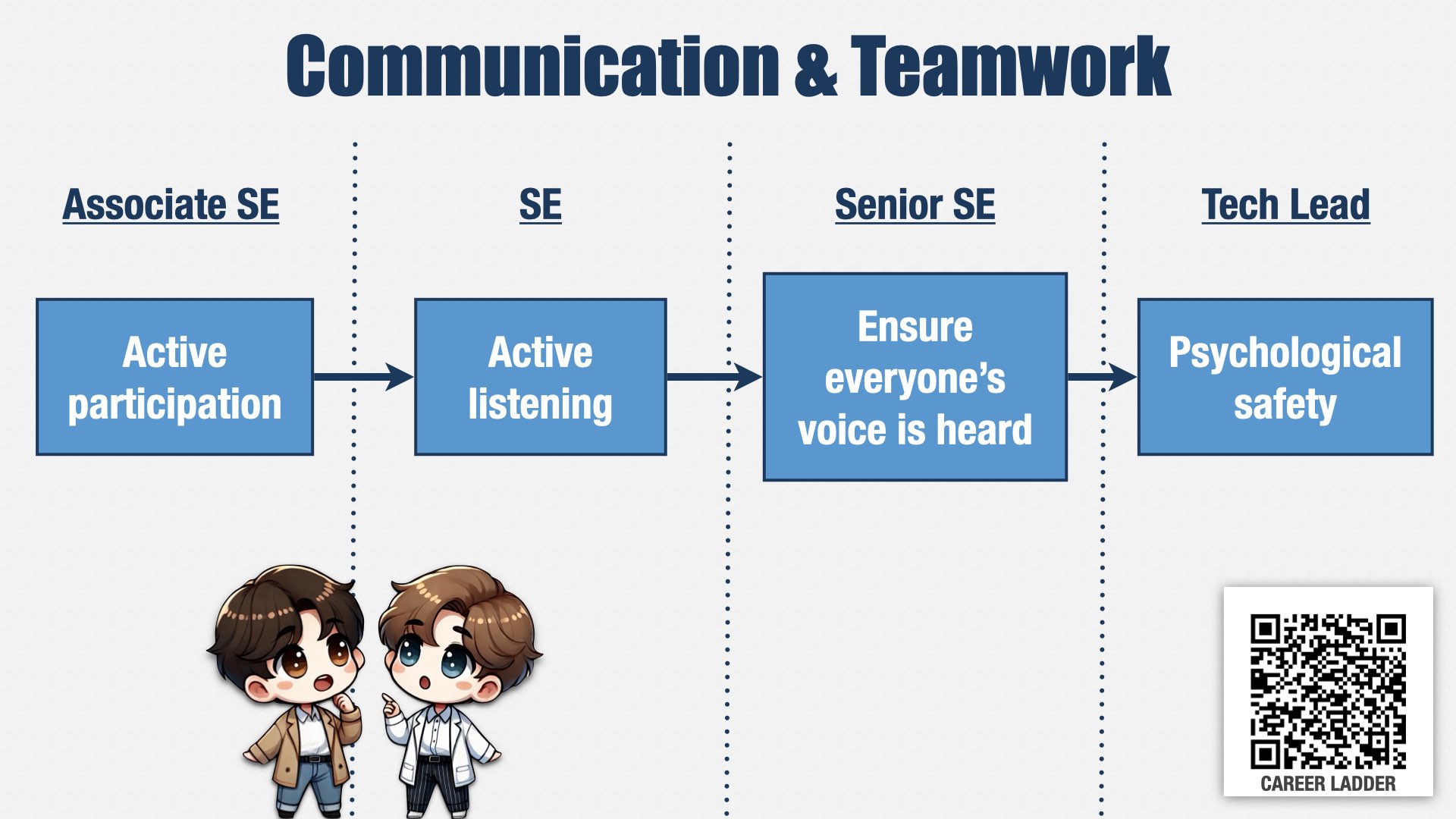
首先是:沟通与团队协作。
在我加入之前,公司把任务分配给单个工程师,然后他们独自干上一两周,回来交付成果。
现在,我们不再把工作分配给个人,而是分配给_团队_。(稍后我会聊到团队是如何定义的。)我们希望这些团队能够拿到“有价值的增量”,然后_一起_工作,包括和产品经理、利益相关者协作去理解需求,以及如何_以团队_的方式来协作和交付成果。
这对公司文化是一场_大变革_!对一些人来说会很不习惯。为了推动工程文化的转变,我们在职业发展路径中定义了很多与沟通和团队协作相关的技能。这张图仅仅是其中一个例子。
一位新进工程师,需要在团队交流中积极参与(active participation)。随着他们的成长,不仅需要表达自己的观点,也要努力理解他人的观点。
进一步成为高级工程师后,他们需要留意谁还没发言,让每个人都有机会表达观点,并且保证彼此都能听到对方。
成为团队最资深的工程师时,他们还要和管理层一起努力,创造一个让大家敢于提出不同意见、感到心理安全的环境。
再提醒一下:我之所以展示这些,是为了改变我所在公司的工程文化。其中有一点是让团队合作更多,而个人单打独斗更少。通过这种随职级而递增的要求,让大家逐步承担更多团队沟通与协作的责任,从而影响公司文化。
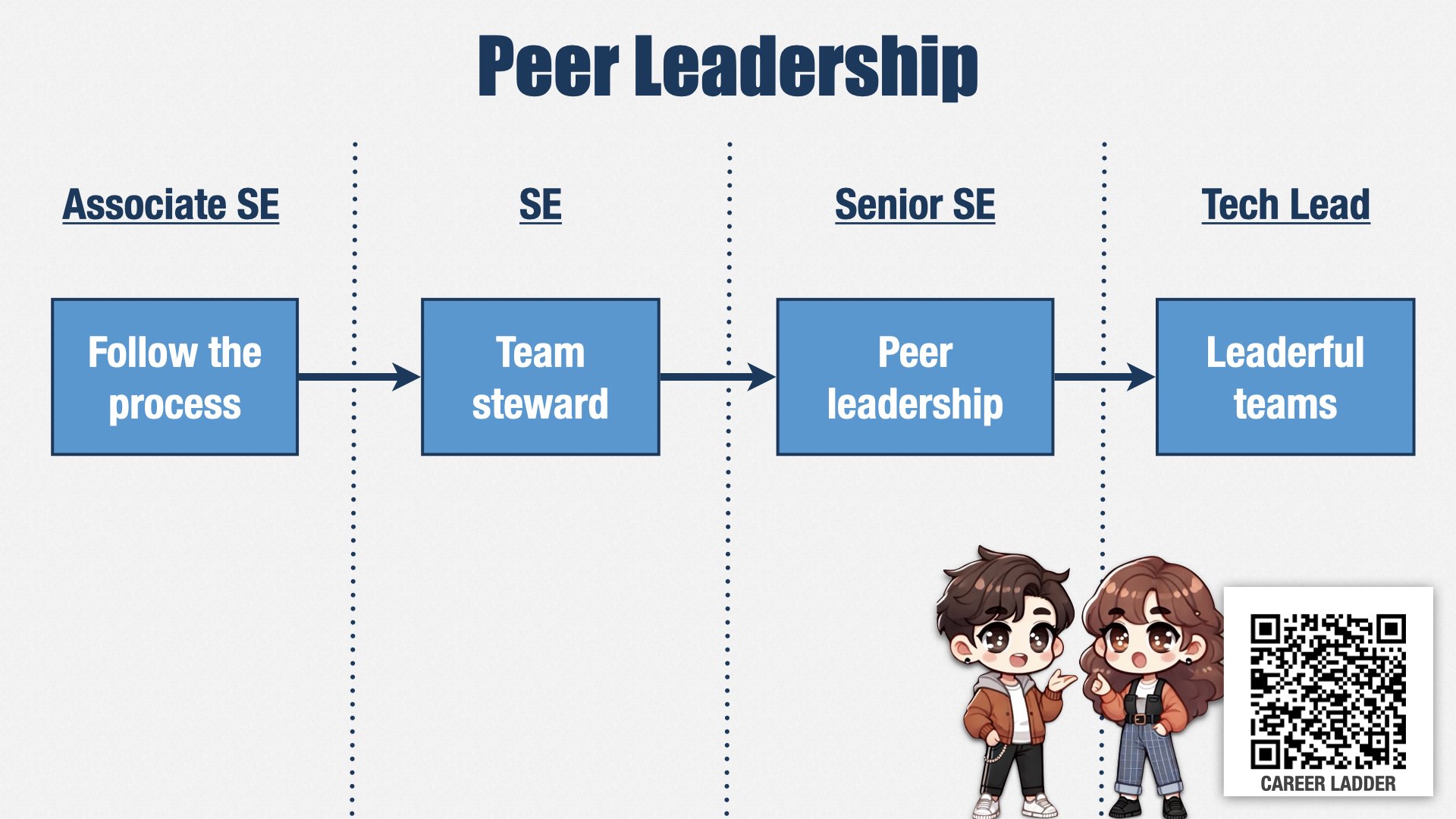
再给大家看一个例子。
如果我们想将决策权下放给执行层,那么“同伴式领导力”(peer leadership)就至关重要。所谓同伴式领导力,就是_团队里的任何人_在合适的时机、针对自己擅长或最了解的领域,都能发挥领导作用,而不需要依赖正式的职位。
我们在职业发展路径里定义了许多领导技能,其中一条路线从最初级工程师开始,就是“Follow the process(遵循流程)”。但这并不仅仅是“按流程做事”,还意味着:如果流程不合时宜,需要和团队一起讨论调整或做例外处理。
随着工程师的成长,他们会开始承担显性的领导角色,比如“Team Steward”(团队管家/管理者)。每个团队有一位“Team Steward”,负责制定团队的工作方式并保持团队成员的一致性。我们希望工程师在职业早期就能承担这样的角色,培养他们的领导力。
高级工程师则需要对领导力有更灵活、更深层次的理解,知道“谁在形式上拥有领导职位”并不是关键,而是根据具体情况选择合适的人带领,其他人则听从他们的建议。高级工程师要能识别在特定情境下最懂行、最适合领导的人,并提升自己在合适场景下承担领导的能力,无需依赖正式职位。
最高级别的工程师会更进一步,与管理层配合,深入了解团队所有成员的领导技能和缺口,帮助他们在最需要的地方提升这些技能。
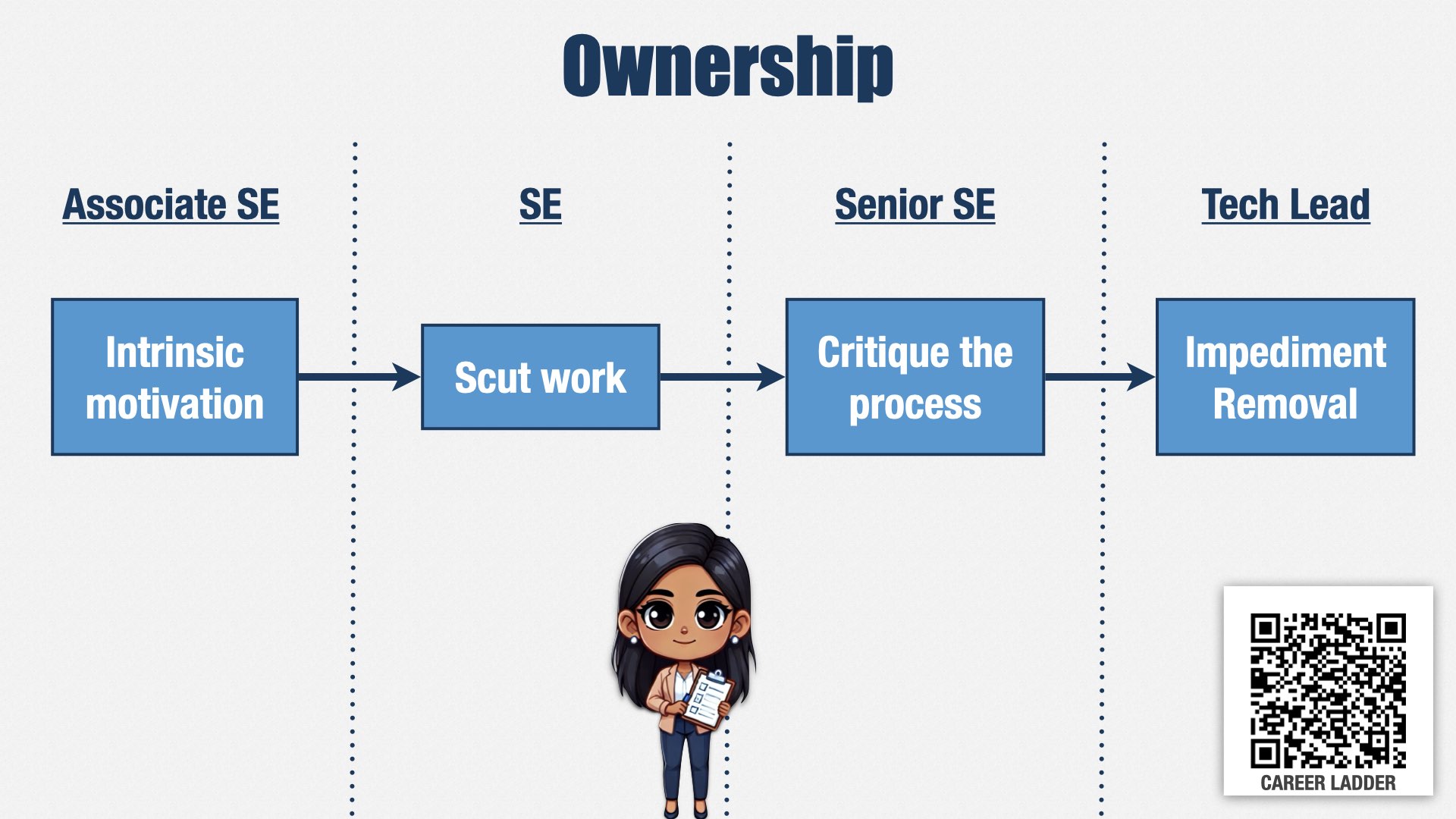
同样地,如果要把决策权下放给执行层,就必须让执行层团队成员对结果足够“自我负责”(ownership)。
这条路径里,一开始是“内在动力”(intrinsic motivation)。我们希望工程师是因为热爱工程、热爱优秀团队,而不是需要被管理者盯着才努力工作。
接着,为了升到中级,他们需要能自发承担那些不那么好玩的琐碎工作。英文里常说的“scut work”,指那些繁琐又枯燥,但非做不可的事。
这种“苦活累活”并非只由初级做,而是所有人都应该承担。我们要看重的是:在_没有人要求_的情况下,是否能主动发现并解决团队需要做的苦差事。
每位工程师都要参加团队回顾(retro),但要成为高级工程师,就要更积极主动地改进团队工作方式和团队与外部的交互方式。他们要对团队改进负起更多责任。
最高级的工程师更进一步,主动识别那些超出团队控制范围的阻碍,协调管理层和其他负责人,一起清除障碍。
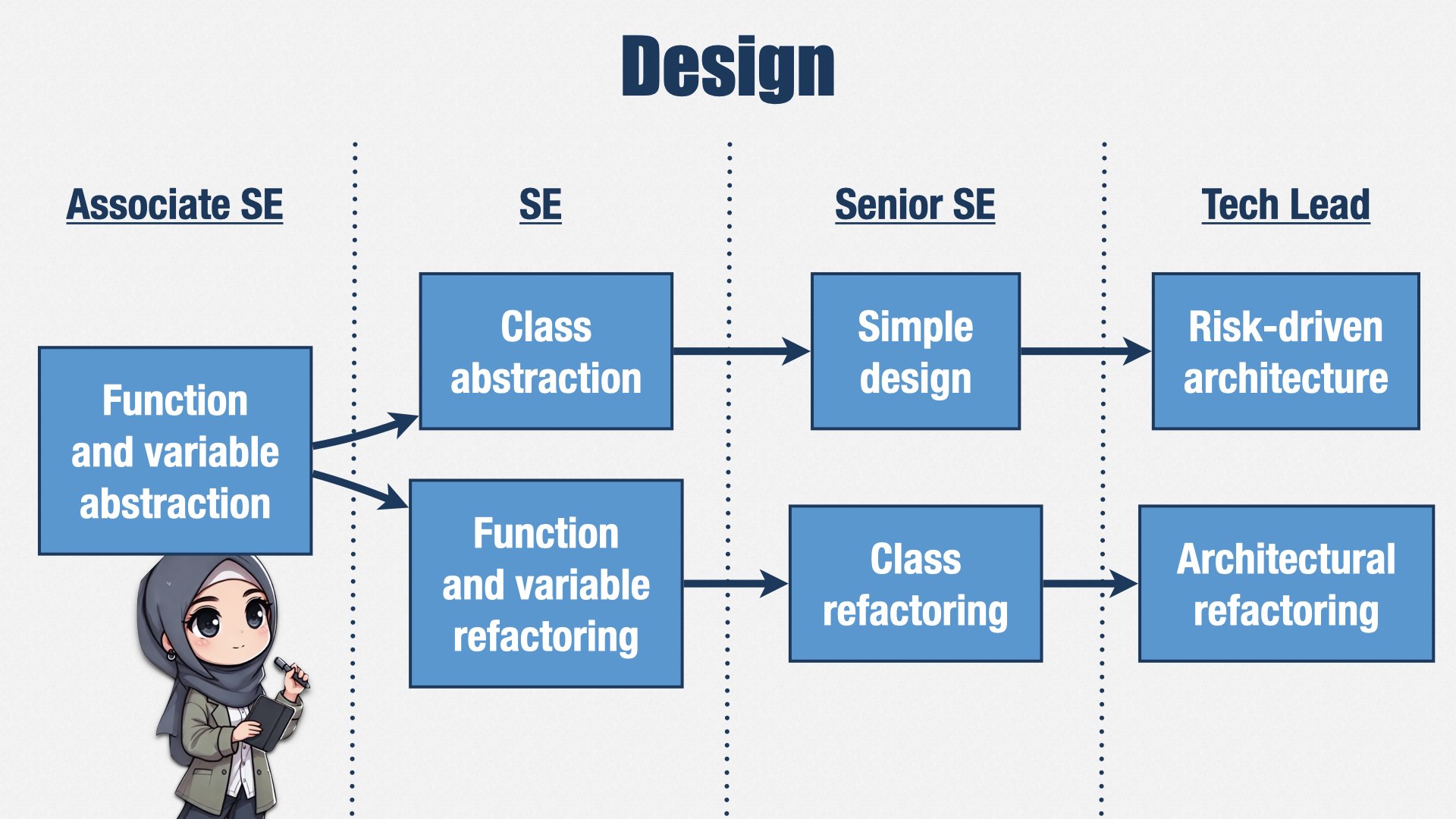
我们也非常重视 XP 的核心技能,尤其是让设计保持简单。这是一个例子。
初级工程师应会用函数和变量让代码更易读。
成长为中级后,需要掌握如何在函数和变量层面进行重构,以及如何创建合适的类抽象。
成为高级工程师后,需要能够对类的抽象进行重构,并利用这些技能来简化系统的整体设计。很多时候初始设计都过于复杂,因此需要经常有人关注如何长期将它简化。
这种对“简单设计”(simple design)的重视和很多公司正好相反。在一些公司,你级别越高,意味着你的设计“越复杂”,好像要证明你有多牛。但我们恰恰相反,认为“制造复杂”很简单,而“保持简单”才最难,所以我们期待资深工程师产出的设计更简单。
最后,最高级的工程师会熟知如何对系统整体做重构,并根据风险和变更成本来优先排定这些重构。
总之,我们的职业发展路径是一个用来推动公司文化改变的工具。我们从原本注重“个人开发”、“高级技术”和“复杂系统”,转变成关注“团队协作”、“同伴式领导”、“主人翁意识”和“简单设计”。
这套新版路径是在去年 6 月上线的,也就是大约半年前。它似乎已初见成效。我的管理层告诉我,他们看到员工行为开始转变,比如有人主动主持会议、承担以前不会承担的工作等。对于表现不佳的员工,我们也可以用这份新路径来作为衡量标准。

当然,职业发展路径本身还不够。它能告诉人们我们对他们的期望,但还需要帮助他们掌握“如何达成这些期望”。
为此,我们组建了一支 XP 教练团队来支持这次改变。我自上任以来获得的空缺编制全都用来招聘非常资深的 XP 教练。他们是_一线_教练,会亲自参与编写代码,作为团队成员的一部分以身作则,示范 XP 是如何运作的,以及为什么这是种非常出色的工作方式。
目前我们的教练和工程师的配比大约是 1:11,还不算理想,但已经够我们开始在内部培养教练,而不是完全依赖外部招聘。并且,随着不断有新职位空缺,我们会继续招聘具备 XP 技能的人才(不一定都非常资深),让他们融入我们的团队。
在我看来,其他公司在这方面常见的问题是投入不足。他们可能会有个“敏捷卓越中心(Agile Center of Excellence)”,但教练与工程师的比例往往在 1:50,甚至 1:100,而且那些教练通常也不是编程出身,没法“示范式”指导。即便他们有编程背景,也人手太少。要想真正学好 XP,需要在真实项目中每天都被浸润、耳濡目染,需要教练在你身边一起干活。“1:50”或者更差的比例显然做不到这一点。
我们公司目前做到了 1:11,而且我希望能尽量接近 1:6。通过最初招聘的一批 XP 教练来开个好头,我们也在内部培训潜在教练,未来继续优化这个比例。

“人员”是任何组织的血液,对于敏捷组织更是如此——因为大量决策是在执行层完成的,而不是经理层。
如果我们是世界上最好的产品工程组织,那我们就要拥有行业最顶尖的人才,也要成为他们最想工作的地方。为实现这一点,我们与众不同地定义了什么叫“最好”:我们注重团队协作、同伴式领导、主人翁意识,以及极限编程中的简单干净设计,而非算法和复杂解法。此外,我们通过全新的职业发展路径和亲身示范的 XP 教练来推动公司文化变革。
内部质量(Internal Quality)

我不会说日语,但我有一个最喜欢的日语单词:muda。我是在丰田生产方式(Toyota Production System)里学到这个词的。
对我来说,muda(浪费)就是最大的问题;对很多公司也是如此。举个例子:
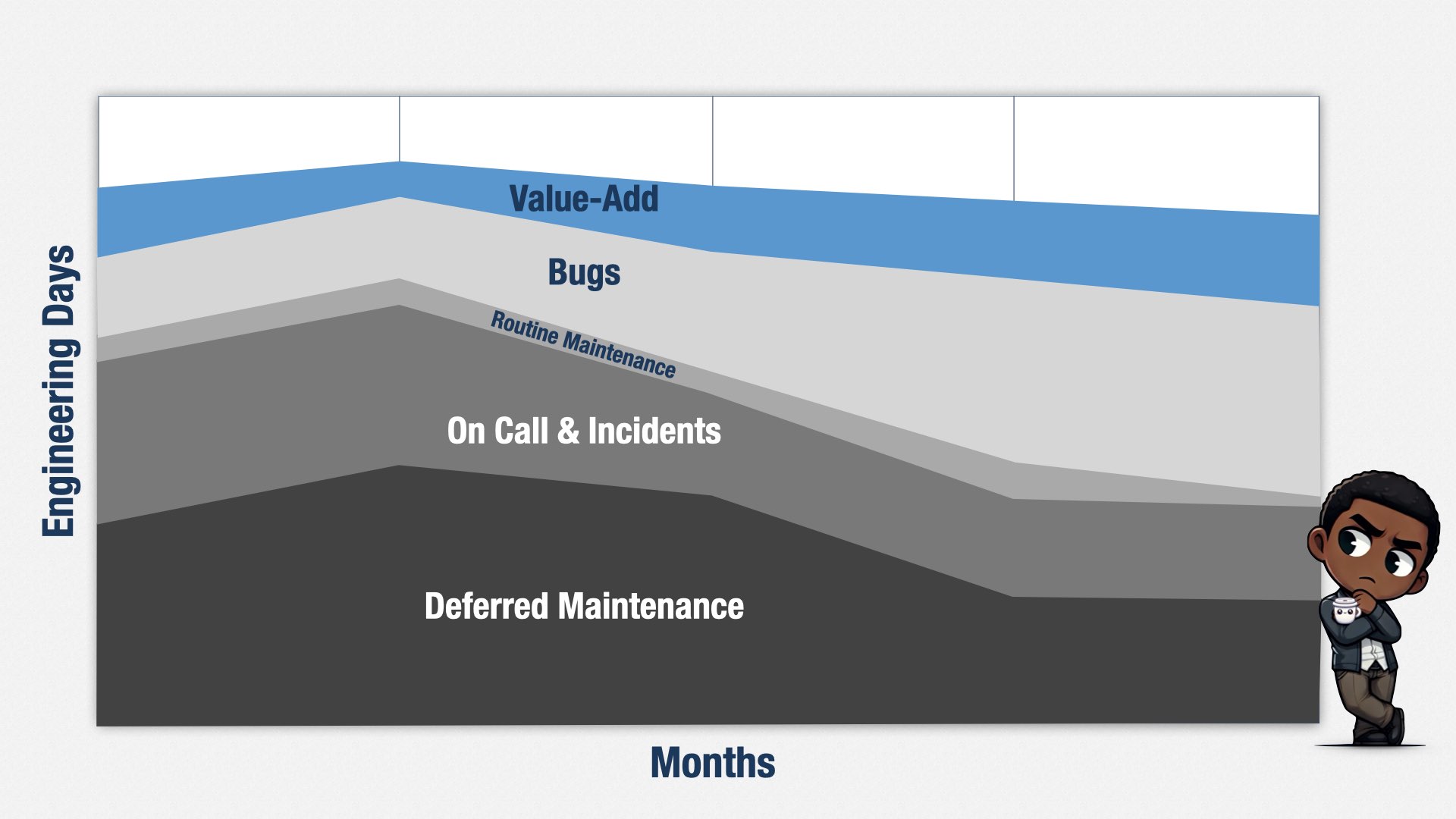
这是一个产品五个月的工程投入(虚构的,用于保密,但是真实案例的写照)。
横轴是时间(月),纵轴是团队在不同工作类型上的投入占比。
在这五个月里,团队大约把 35% 的时间花在“延期维护”(Deferred Maintenance)上:有个关键技术因为没有及时更新,供应商停止了对旧版的支持,团队只能暂停其他所有事情来升级或替换它。
另有 25% 的时间花在“值班和处理线上事故”上。
5% 的时间花在“常规维护”上。
20% 的时间花在修复 bug 上。
只有大约 15% 的时间花在为业务创造新价值上。
换句话说,如果这家公司在此期间的开发成本是 100 万美元,其中只有 15 万是花在对业务真正有价值的新东西上;其余 85 万都算是浪费——不得不做,但却不能直接体现价值的工作。这就是 muda(浪费)。
这就是我喜欢“muda”这个词的原因:它正是我急需解决的那个问题。

为什么会有这么多浪费?我总结了三个常见的根源:
复杂度(Complexity)
反馈循环过慢(Slow feedback loops)
延期维护(Deferred maintenance)
人们常把它们都混在一起说成“技术债”或“遗留代码”,但其实它们是各自独立的问题。让我们分别看看。
1. 复杂度(Complexity)
复杂度源于有太多不同的系统,没有哪个开发者能全面理解所有系统。大家只能小心翼翼地工作,速度变慢,即便如此,还是会出现 bug 和线上事故。
我们的系统其实_没必要_这么复杂。为了加快交付进度,之前选用了许多功能强大的复杂技术,一次次地叠加。每种技术都需要专门的知识,导致没人能面面俱到,也难以让这些工具协同工作。
很多公司在规划新功能时只关注“搭建”功能的成本,而忽略了“维护”成本。他们经常选那些“实现快、维护难”的技术栈。而软件开发的主要花费其实在于_维护_阶段,而非_搭建_阶段。忽视维护成本会让他们日后陷入更大困境。
到了 2025 年,我们无法回避一个话题:AI。它对开发成本的影响不可小视。别误会,AI 是很好的工具。我也用它做了本演示文档里的图片,这些有趣的 Q 版形象都是 AI 生成的,我自己是做不出的。
然而,你或许发现了图片中有些诡异的地方——比如角色的头发里藏了只眼球,或者额外多出一只手。
这些可见的失误尚且容易觉察,代码层面的 AI 问题就更隐蔽了,依然关系到“快速构建 VS 维护成本”的取舍。
用 AI 写代码的确可以快,但让所有代码干净地组合在一起却很难。如果你依赖 AI 写代码,你是否考虑过后期维护?你又如何培养初级工程师的技能?
或者你想做“AI 内容生成”之类的功能,做起来似乎也不难,但如何对提示词(prompts)进行微调,以及 AI 引擎变动后如何维护、怎样实时发现它“不好使”了,这些都是需要人力成本的。
2. 反馈循环过慢(Slow Feedback Loops)
本质上,复杂度来源于只顾“搭建”而忽略“维护”,后果非常严重。让我们再看第二个导致浪费的问题:反馈循环过慢。
所谓反馈循环,指的是开发者修改代码后,到验证修改是否达成预期结果,需要花多少时间?如果少于 1 秒,那么他们可以针对每次改动都进行验证,哪怕是一行代码的变动。这正是测试驱动开发(TDD)带来的神奇体验。来给你看看实践中的例子:
二维码:Fast Tests
这是一个真实线上系统的完整构建过程。代码量不算特别大,但也有 12 年的历史,足够积累一些“技术债”。我们来看看它的构建需要多长时间:别走神,这非常短。
[播放视频] https://2.media.letscodejavascript.com/video/jamesshore/best-product-engineering-org/full-build.mp4
就这样,编译和测试全部完成,一共才 8 秒多。
在我所见的大多数组织里,8 分钟就算很快了,而且实际往往更慢得多。
之所以这么快(或者说,别的公司为什么慢)主要与测试有关。多数团队的测试又慢又脆弱。这套代码有 1300 多个测试,但也只花了不到 3 秒。
想要如何达成这些速度,讲起来就是另一场演讲了。不过我在我的网站有很多资料,感兴趣可以通过 jamesshore.com/s/nullables 或幻灯片上的二维码查看。
https://2.media.letscodejavascript.com/video/jamesshore/best-product-engineering-org/watch-build.mp4
8 秒很快了,但其实对顶尖开发体验来说,还是有点长。理想情况是让构建时间低于 5 秒,甚至 1 秒以内。这样开发者就能在写每一行代码后,马上验证是否存在问题,一旦发现错误立刻就能知道是哪一行代码,基本不需要复杂调试。
接下来再给你看一个例子,展示了“秒级”反馈:
[播放视频]
这样,每次增量构建只需要不到 0.5 秒。
当然,这里也有一些技巧:首先,构建会自动监听文件变化;其次,它是用真正的编程语言写的,能常驻内存并缓存大量信息,例如文件位置、时间戳、文件依赖关系等等。这样当检测到改动时,就不必重新扫描整个文件系统,只测试受影响的代码。
[停顿]
老实说,我们有些代码已经做到这种秒级反馈,但在浪费最严重的系统里,依然要好几分钟甚至十几分钟才能完成一次可用的测试环境。于是人们就不想在每次写完一行代码后都去验证,而是攒一堆改动后一起测试,再慢慢调试,这导致了大量浪费,也常常让 bug 流到生产环境。所以为什么说“快速反馈”如此重要。
3. 延期维护(Deferred Maintenance)
第三个导致浪费的问题是“延期维护”。它其实是前两个问题的合并结果。如果系统简单,那么升级关键依赖就很容易。但很多公司技术栈很复杂,有些升级还需要大的架构改动。
同样,如果反馈循环很快,你就能快速而安全地做出变动。但大多数公司的循环又慢又贵,所以升级过程往往得花很久。
一次大升级再加上改动缓慢,往往需要花好几周甚至几个月,管理层只好在“重要新功能 VS 更新组件”之间做艰难取舍。许多时候,业务伙伴宁可先把升级搁置。而这又会带来更多维护上的麻烦,陷入恶性循环……
……最终所有账单会一起到期。
我们该怎么办?复杂度、慢反馈、延期维护——这是很多公司都遇到的普遍难题,人们也常说“遗留系统”、“技术债”之类。不管叫什么,本质都是内部质量低下、浪费高企。

我见过四种方法来修复低内部质量:
大爆炸式重写(Big bang rewrite)
模块化重写(Modular rewrite)
需求驱动重写(Change-driven rewrite)
原地改进(Improve in place)
注意:前两种做法很常见,但往往失败或风险极高。

“大爆炸式重写”的流程是:新建一个团队来开发新系统,原团队继续维护旧系统。在新系统完成后,旧系统就下线,换用新系统。
理论上看起来不错……
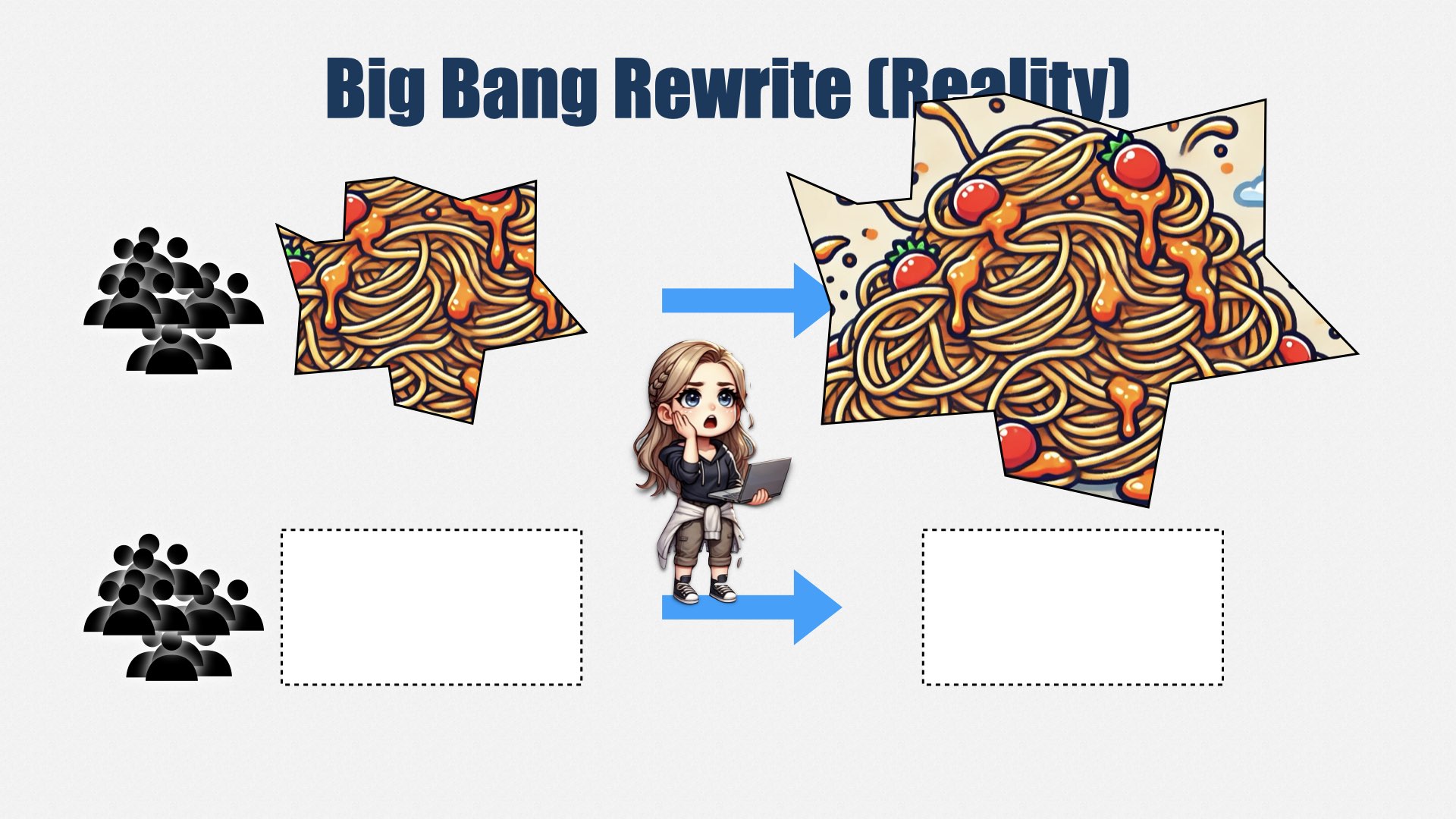
但实际中,新系统总是比预期花的时间更久,而旧系统还在不断堆积更多复杂度,因为大家觉得“反正要被淘汰了”,结果越发混乱。同时,你要维持两拨团队,开销剧增。最后不是新系统被砍,就是匆忙上线,结果功能不足,客户抱怨不断。即使新系统比旧系统好一点,也“好”不到哪去,不久后还得继续重写。

因此,我极不推荐大爆炸式重写。
另一种不算太罕见的方案是“模块化重写”。
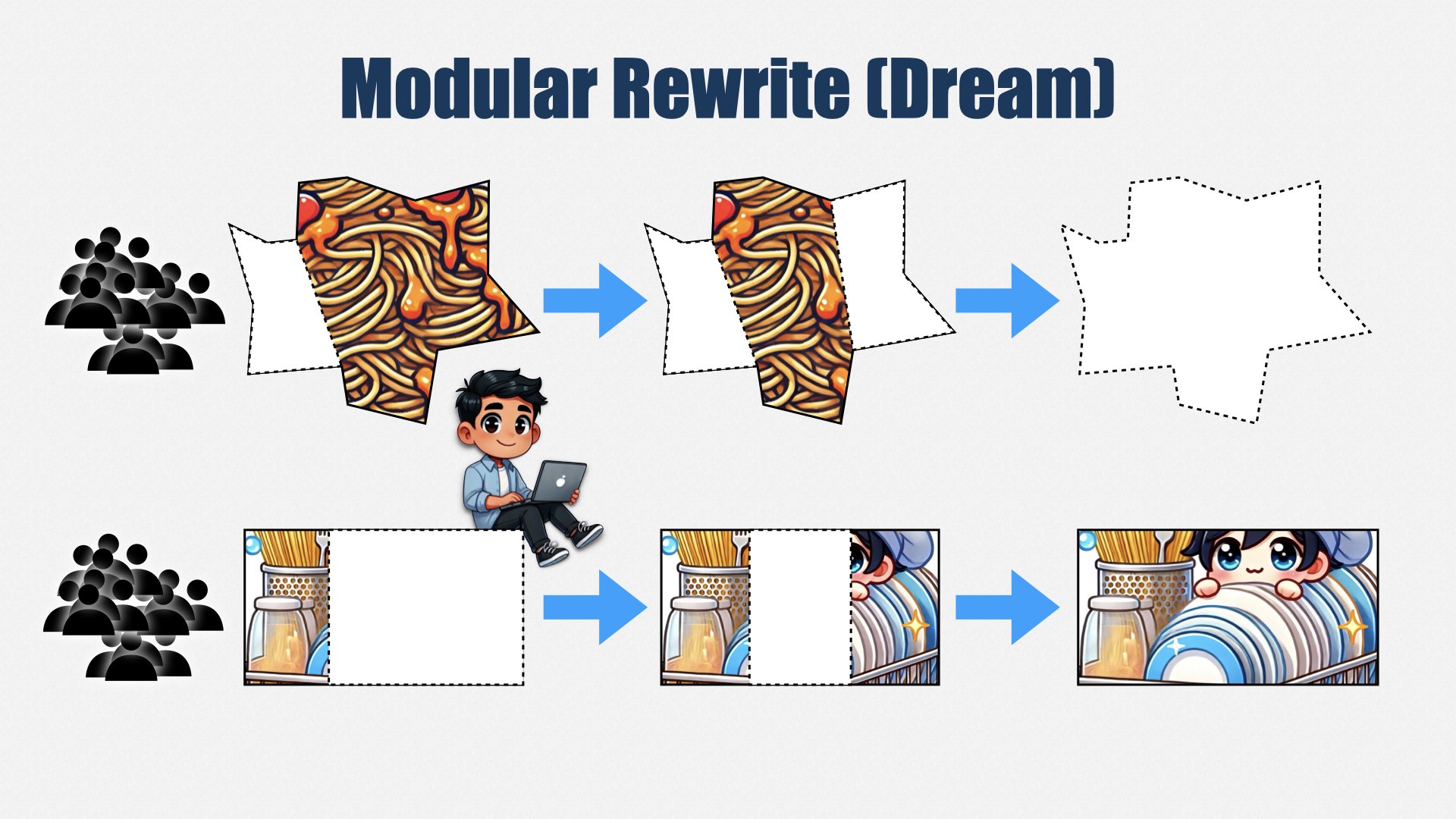
模块化重写会从大系统里划分出一个个子系统来替换,然后再一个个重写。比大爆炸式要安全些,因为它拆分成若干小项目。
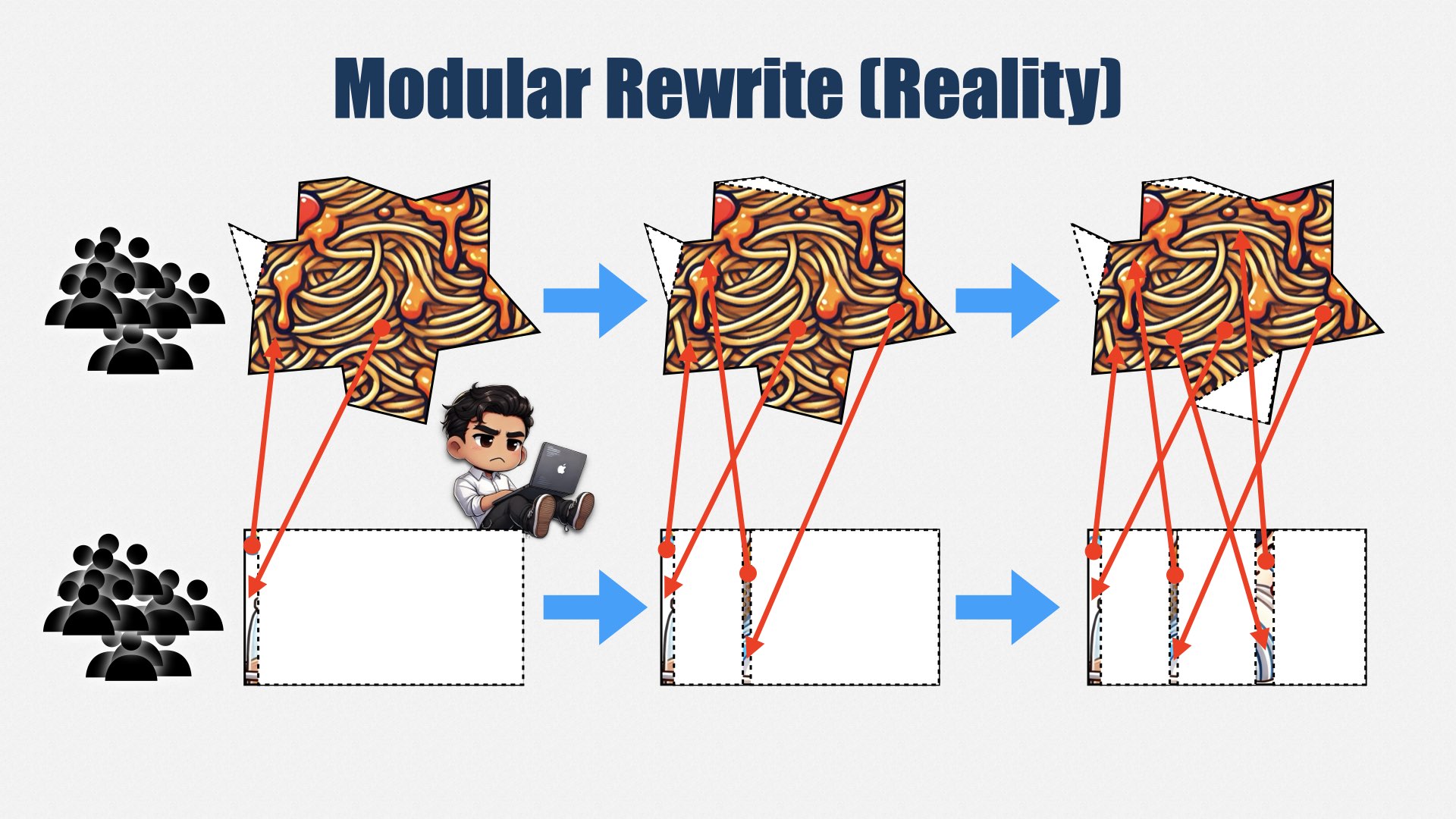
可现实中,“核心部分”往往还是那么难动,只能啃点边角料。万一优先级一变,重写搞到一半就停了,结果原本一个大杂烩,现在变成更多互相连接的子系统,反而更乱。

模块化重写比大爆炸安全点,但也要面对同样的风险:只要没做完,就可能落得一个更大更乱的系统。
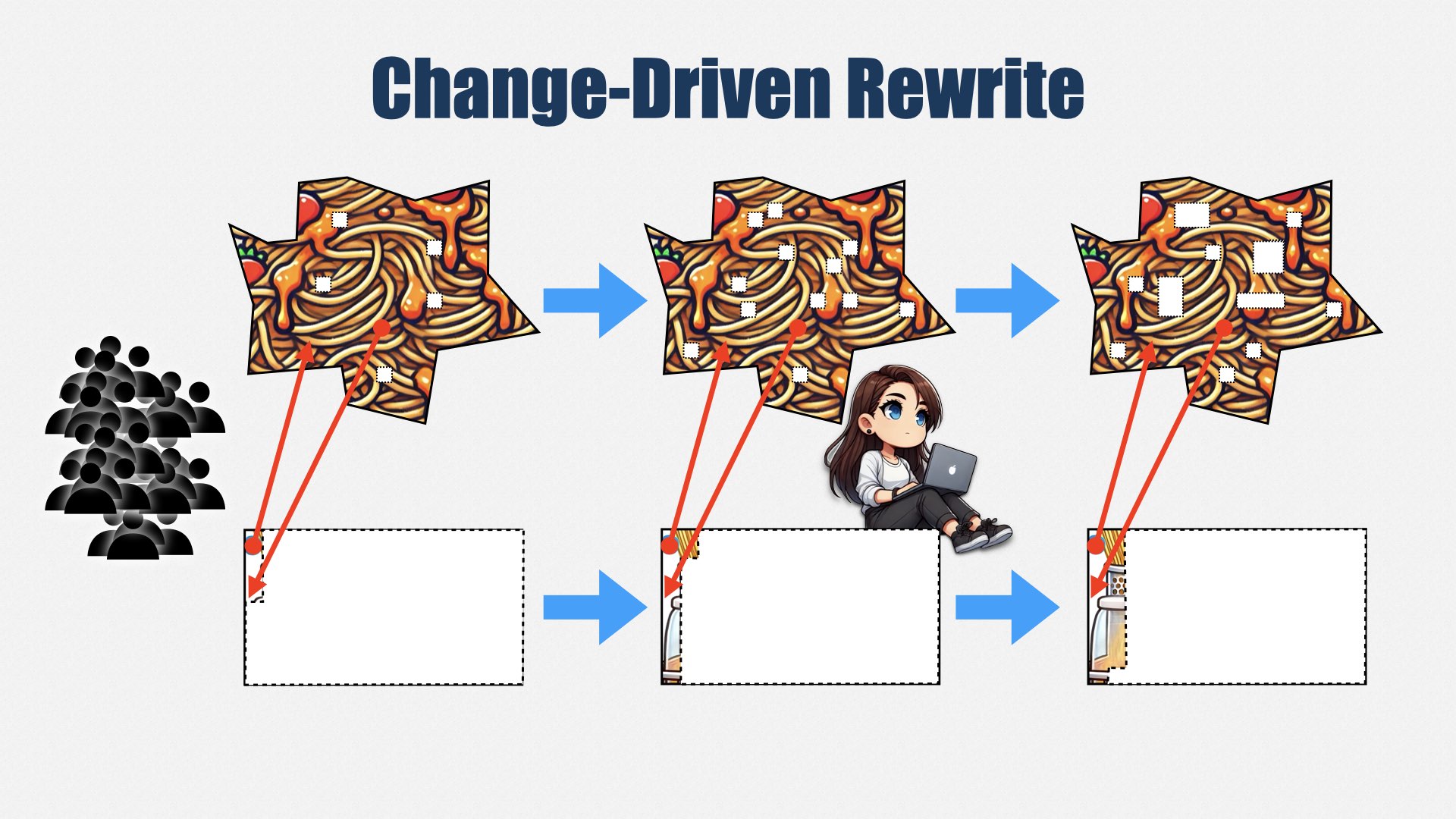
重写的窍门在于,不要和业务需求竞争预算。而是让_同一个_团队一边开发新功能,一边维护旧系统。每当要修改某部分代码时,就把那部分迁移到新的结构里。不要把它当成一个“重写项目”,而是把它视为完成新功能或修复 bug 的一部分。
这样一来,你根本不需要去跟业务争预算,也没人会整天追问“重写什么时候完成”……因为我们并没有一个“大重写项目”。虽然整个过程会很漫长,也许需要几年,但我们可以先把最常改动的 20% 代码清理到位(80/20 原则),足以带来极大收益。

更好的一种方式则是“不重写”——就地改进。继续在现有系统上写新功能或修 bug 的同时,补充测试、完善自动化构建、逐渐改善糟糕的部分。它永远不可能变得“完美”,但由于二八定律,你常改动的部分自然会改进得最好。
还记得我之前展示的那个 8 秒构建吗?那其实是一个 12 年的老项目。早年也曾乱七八糟,但因为我们持续一点一点地改进,现在反而比刚开始时好得多。

如果你们公司存在内部质量问题,最佳做法是_就地改进_。当然,这需要一些特定的技能,所以可能需要引进拥有这类技能的人才。就像我雇用了许多 XP 教练,也一直在培养团队。
有时候,你确实无法就地改进,比如想把编程语言或框架换成根本不同的技术栈,只能做“需求驱动的重写”,在对旧系统做修改的同时,将其迁移到新系统。
模块化重写和大爆炸式重写不是没可能成功,但风险高。我不推荐。毕竟前者可能会导致系统更加松散和复杂,后者则可能半途而废或无法满足客户需求。

如果我们是世界上最好的产品工程组织,那么我们的软件就会非常易于修改和维护,也不会有 bug 和宕机。
虽然现实还差得远,但我们努力的方向有三点:
简化技术栈。 关注维护成本,而不仅仅是开发成本。
改善反馈循环。 搭建能让开发者在 5 秒甚至 1 秒内完成构建和测试的环境,并引入 TDD 等实践。
不再延期维护。 一旦有依赖的新版,立刻升级。不用“排优先级”的方式去争取,不做的话就像丰田的“停止生产线”。虽然我们还没完全做到,但随着技术栈变简单,开发者体验变好,升级会越来越容易。
对于现有系统,如果要大动干戈,我们尽量_不_搞大规模重写,而是在现有系统上_逐步改进_。确实无法就地改进时,才采用“需求驱动重写”的策略。
可爱度(Lovability)

Jeff Patton 也在本次大会!他明天会做主题演讲,我以前听过他的演讲,绝对值得一听。
Jeff 对如何让软件更惹人爱有更深的洞察,我在这里主要谈谈如何腾出时间来运用 Jeff 的想法。
我们刚才聊了很多关于内部质量和减少浪费。内部质量越高,团队效率越高。所以对内部质量的投资很容易理解——越多越好。主要需要考虑的是现金流和进度的平衡。
“可爱度”说的则是_外部_质量,即让我们的用户、买家、内部使用者爱上我们的产品。但我们永远会有比时间更多的想法,所以“可爱度”也包括理解利益相关者的_真正_需求,并把有限的精力放在最重要的地方。

这其实是很早就被行业意识到的。敏捷出现前,许多公司会花巨大精力做需求分析,力图“确保”构建的东西是正确的。他们会研究市场,详细定义要做什么,然后再去实现。
那些没经历 90 年代软件开发的人,可能以为“瀑布式开发”只是个传说——其实很多公司如今依然这么做。只不过现在会把需求文件拆成一堆 Jira ticket,然后来回拖拽,但骨子里还是“先分析后实现”。

这就是所谓的“项目式治理”(project-based governance):先做一个计划,再照着做,然后对比实际进度和原计划。
在这种思维里,若能按时、按预算、按规格交付,就算成功。
但 2006 年《CIO Magazine》上有一篇 Ryan Nelson 的文章说:
那些在传统标准(时间、预算、规格)下被视为成功的项目,最终也可能是失败的,因为它们并没有赢得目标用户的认可,也没有给业务带来多少价值……同时,一些在传统 IT 度量中被视为失败的项目(比如超支或延期),却可能因为实际带来了用户喜爱或意想不到的商机而成为成功案例。
——《CIO Magazine》,2006 年 9 月

我最爱举的例子之一就是 FBI 的“Virtual Case File”系统,因为它经历过美国参议院的调查,很多细节都有记录。虽然它很高调,但其实是那个时代的典型案例。
2001 年 6 月:项目启动
17 个月后(2002 年 11 月):才“搞定”了需求
又过了一年(2003 年 12 月):交付了产品,但 FBI 马上发现系统无法使用
2005 年 2 月:正式取消,浪费纳税人 1.045 亿美元
这里的问题并不在于软件本身没功能,而是他们在这么漫长的需求阶段里,分析出的内容根本不符合 FBI 的实际需求。

你可能会说:“那是过去式……我们是敏捷啊。”可实际上,很多自称“敏捷”的公司依然用这种“项目式”思维,依然评估是否按时按预算交付……
[停顿]
这种方式的根本问题在于,我们无法在做之前就百分百知道用户或客户想要什么,我们只能_猜_。有的猜对,有的猜错,我们必须用实验去验证哪些想法值得投入。
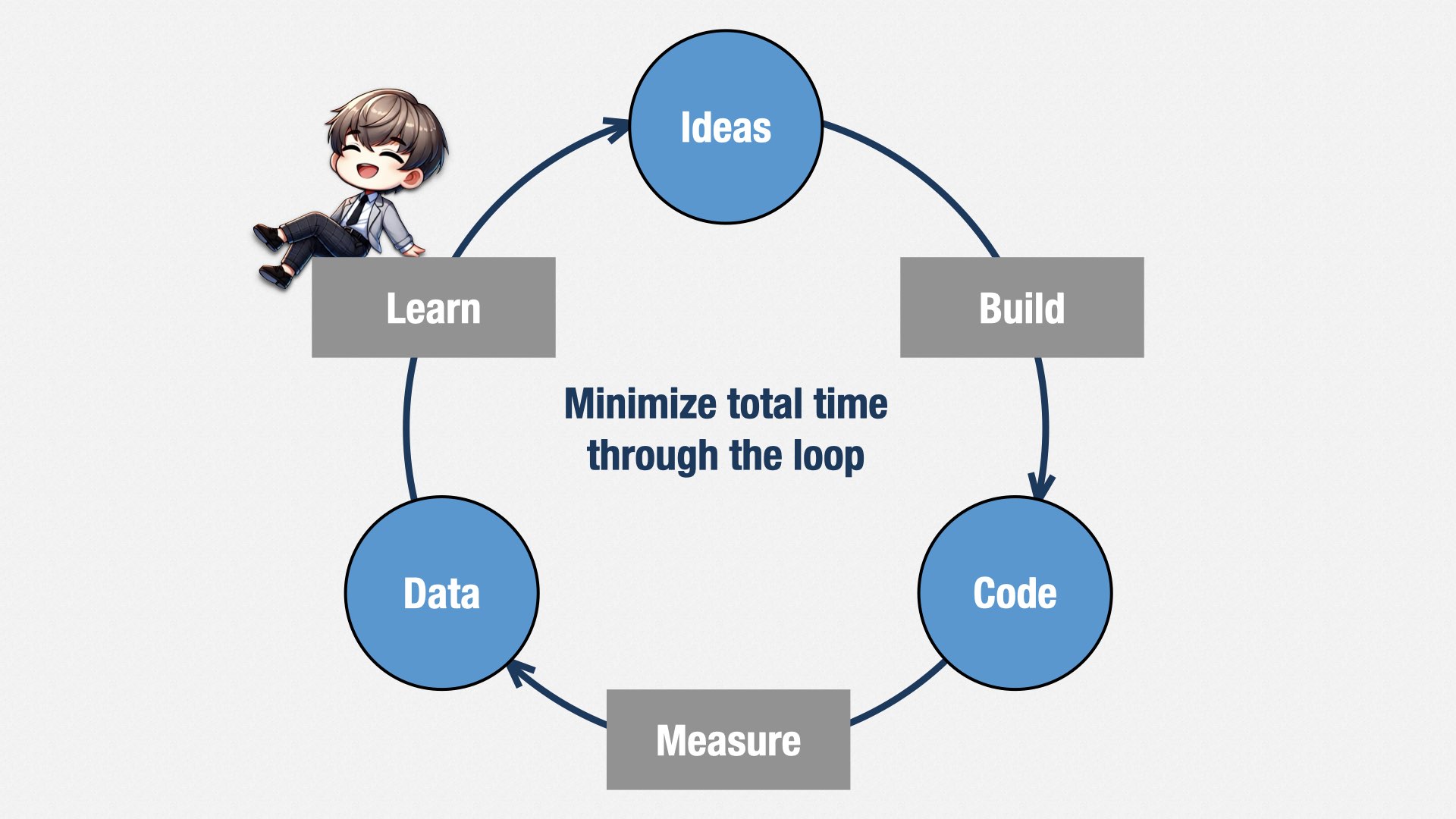
我很喜欢 Eric Evans 的“Build-Measure-Learn”循环:我们先有一个想法(Idea),然后做个最小化的实验(Build),可能只是用户访谈、问卷、Figma 原型等,然后得到数据(Measure),从数据中学习(Learn),再改进想法(Idea)。
这也是“最简可行产品(MVP)”的由来。但经常被误解:MVP 不是把一个小功能直接丢给用户,而是做一个最小_实验_来验证我们_要给_用户做的功能。因为我们的目标是“加速学习”,而只有越快地走完这个循环,才能越早淘汰错误想法、少走弯路。

这就引出“产品式治理”(product-based governance)。而不是制定一个宏大计划并硬着头皮执行,我们更倾向于一系列小规模计划,通过不断学习和调整来逐步靠近目标。
成功的标志不再是“按计划”,而是“让用户满意、对业务有影响”。

能随时调整计划是敏捷的核心之一。Martin Fowler 说过:
“敏捷开发是适应性的而不是预测性的,侧重于人而不是流程。”
可惜,现实里很多公司用上了 Scrum、开着日站会、自称“敏捷”,却仍然在做着“预测而非适应”、“以流程为中心而非以人为中心”的事情。如果你不适应(adaptive)、不以人为本(people-oriented),那就不算敏捷,不管你有多少所谓的“Scrum Master”和“迭代”。
[停顿]

战术层面的 Build-Measure-Learn、快速迭代很重要,那高层战略呢?我们公司是由“领导团队”(Leadership team)来制定战略,包括 CEO、产品负责人、营销、销售、合作伙伴、内容、财务等部门的负责人。
这里很需要达成一致。每个人对自己领域都有一套想法,比如产品想改善可用性、营销和销售想要闪亮的新特性、财务想自动化账单……优先级不同,怎么平衡?工程团队的资源又怎么分配?
我们正在尝试一种“产品押注(product bets)”的方法。

一个产品押注就是一个宏观层面的假设。比如,销售负责人可能说:“我们的客户里有不少吸血鬼。要是我们能提供夜间 AI 销售代表,也许能搞定更多单子。”
(其实我们的客户不是吸血鬼;这是为了保密而编的例子。也可能是狼人。)
产品押注会写成一个一页纸的简单概要,包括:
论断(Thesis):用 AI 夜间销售代表提高吸血鬼订单
发起人(Sponsor):销售负责人
预期收益(Value):通常和一个财务模型绑定
推理(Reasoning):比如“吸血鬼每年花 8000 万美元在类似服务上;如果我们直接面向他们,而非面向他们的人类仆从,就能抢占至少 1% 市场份额”
下注金额(Wager):最多愿意为它投入多少钱

领导团队的其他成员也有自己的优先级和“押注”,所以自然会提出异议。
比如:
内容负责人: “吸血鬼从来不自己购物,那是他们仆人的事。”
营销负责人: “AI 还不够格做销售。”
财务负责人: “这恐怕要花超过 40 万美元吧。”
我们欢迎这些质疑。我们希望领导层能畅所欲言,给出理由,从而让押注更稳健。

如果最终这个押注得到通过,那么大家的意见就会变成一个个可验证的实验。“吸血鬼不屑自己购物?”我们就去证实或证伪。
假设:他们会喜欢夜间销售这种尊重。
实施:我们不写代码,而是先让真人销售尝试夜班。
测量:看看这样做后,吸血鬼客户的销量如何。
如果销量翻了 5 倍,那就说明这个策略可行。

再看另一个反对意见:“AI 做销售不行。”
假设:虽然不如真人,但“差不多”就够。
实施:仍不直接写软件,而是在 ChatGPT 里写个自定义脚本,让夜班销售员测试一部分用 AI 脚本,一部分不用。
测量:看看销量有何差别。
比如测出 AI 脚本使销量从真人夜班的 5 倍降到 2 倍。这说明夜间销售值得做,但 AI 做销售不行。于是我们省下了可能高达 40 万美元的研发投入。

总结来说,产品押注是我们帮助领导团队进行战略优先级决策的工具。
不过老实说,到目前为止,这个想法推行得很慢,还在试验中。所以今天分享时,你要谨慎参考——这是我们正在摸索的一套方法。
如果能奏效,它不仅会是战略上的优先级工具,还可以促进领导层对他们想法的批判性思考,帮助生成具体可在 Build-Measure-Learn 中验证的假设。

如果我们是世界上最好的产品工程组织,那么我们的用户、客户、内部使用者都会爱上我们的产品。而且,我们必须深刻理解利益相关者的需求,把有限的精力花在最能带来价值的地方。
想做到这点,第一步要在领导层达成战略共识。我们在尝试用“产品押注”来完成这个目标。它不仅能帮助我们确定优先级,还会督促团队对假设进行批判和实验思考。
第二步就是进行验证并根据结果调整计划。我们采用“产品式治理”,不再盯着“是否按原计划交付”,而是关注价值影响。我们用 Build-Measure-Learn 循环尽可能快速、低成本地完成假设验证,最好不写代码就能完成。
可见度(Visibility)

由于工程资源永远有限,总有项目排在前面,也就有项目被延后。有些人欢喜,有些人忧,有些人恼火。
透明度对赢得内部利益相关者的信任至关重要:我们把时间花在哪儿了?为什么这么分配?我们固然会发各种报告,但不够,还需要主动和大家沟通,理解他们的立场,分享我们的考量。
但即使这么做,也一定会有人不开心。常言道,“你无法让所有人都满意”。
老实说,我在如何构建这层“信任”上没有什么绝妙方法。我选择这家公司,本来就是因为创始人对我非常信任:我们 15 年前共事过,他们知道我的风格,也支持我。
然而,创始人的信任并不代表整个管理层都信任我。毕竟 15 年后公司大变样,大多数领导都不认识我。
况且,创始人和我想要推行“产品式治理”和“Build-Measure-Learn”,可其他领导层却想要“确定性”。他们评判工程团队是否可靠的方法很简单:答应的功能能否如期完成?就是他们所谓“按时交付”……
可惜,工程团队当时并不能按时交付。
团队没能按时交付有很多原因:一方面他们对预估缺乏有效方法,另一方面我也不打算追求“可预测”——“可预测”更像项目式治理,而我想要的是“产品式治理”。
“产品式治理”在想要“预测性”的人看来很难接受。因为我们不知道在_这一步_(Build)会遇到什么,直到_测量_(Measure)和_学习_(Learn)之后,我们才知道下一步要怎么做。
当然,如果我们完全可以预测下一步要做什么,就意味着我们没有学到新东西,而那就浪费了“适应性”的机会。

所以有句话很形象:“唯一能赢的招数是不玩这场预测游戏。”
……下盘国际象棋怎么样?
我上任后首先带来的改变之一,就是打造更严格的预估方法。但在此期间,我告诉团队:先不要再给任何人提供完成日期。
这在利益相关者间当然不受欢迎。
他们其实不是真的需要那些日期来做什么,而是把这些预测当政治武器:“你当时承诺了 X 月份完成!”“呃,是领导团队后来把这个优先级排后了啊。”“我不管,反正你说过 X 月份搞定,这对我比那个新需求更重要!”
所以这类预测反而造成了内部冲突。
如今我们的新预估方式已经建立,但我们还是不给出确切日期,而是给一个范围:“根据历史数据,这个‘有价值的增量’通常需要 2 到 6 周。”
但我们绝不会预测“何时开始”。举个例子,我有个利益相关者一直等一个对他非常重要的项目,可因为其他需求更紧急,一再往后排,他非常不爽,就问“到底什么时候能做好?”我说“从开始做那一天起,2~6 周内会做完。”他又问“那啥时候开始?”我说“看领导团队怎么排优先级。只要他们排上了,我们就能立刻开始。”
他依旧不爽,但他现在对的是整个优先级流程发难,而不是冲工程团队发泄。我觉得这算一种“进步”。

大多数人都希望看到确切交付日期。之所以我能顶住压力不提供,是因为 CEO、CTO 和 CPO 支持我。他们理解自适应规划的价值,也信任我的领导力。这正是我当初五年内看了无数公司后,最终选择加入他们的原因。
CEO 对我的另一个支持,是他在某次领导团队季度会议上给我 4 小时的演讲时间,让我好好谈谈敏捷。在此之前,我都会参加领导团队的季度会议,但从没拿到这么长的讲解时段。
我用了那 4 小时阐述了“muda”以及我们工程产能不足的原因,解释“产品式治理”,并让大家玩了一个游戏。
那个游戏叫 “Agile Fluency Game”,能让玩家体验初学敏捷团队的历程。其中一个主要教训是:如果不小心管理维护成本,会被浪费拖垮。和我们公司当时面临的情况颇为相似。
在那次会议之后,我在公司内部的处境有所好转。我还不能说所有人都信任我,但至少他们理解了我们为什么不给出他们想要的东西,也理解我们为什么要做自适应规划,至少也愿意尊重我……或者说愿意尊重创始人对我的信任。

不过未来的路还很长。2025 年我们会重点推进“产品押注”和战略规划,我会帮领导层做每个押注的成本与收益模型,并基于我们“产品集群”(product collectives)的产能做预估,帮助他们理解不同优先级决策会如何影响工程资源。
我希望这个过程能进一步加深对彼此的信任和透明度。虽然需要时间,但没有信任就无法成功。

如果我们是世界上最好的产品工程组织,内部利益相关者会信任我们的决策。现在还远远没到那一步,主要还是因为产能有限,以及优先级竞争带来的不满。
我也不是什么政治高手,能想到的就是:先找到那些相信我的人(例如公司创始人),对产能问题充分透明,给大家亲身体验为什么会这样。
与此同时,我坚持我们的方向:人们常常想要预测,但我会继续强调自适应。我也会提供范围预估,是基于“历史数据中估算与实际情况的对比”得出的。不过,我只会预估从“开始之日”到“完成”所需的时间,不会预测具体开始时间。
对我而言这是可行的,你那边的情况或许不同。或许你的 CEO 就是不肯放弃预测。那可能需要你先给一些妥协的方案。不过,不管怎样,希望你能从我们的实践中得到一些思路,然后再去适配你自己的环境。
敏捷性(Agility)

如果我们希望经常调整计划、进行 Build-Measure-Learn,那么必须有足够的技术能力来支撑。这里可以分成战术层面和战略层面。
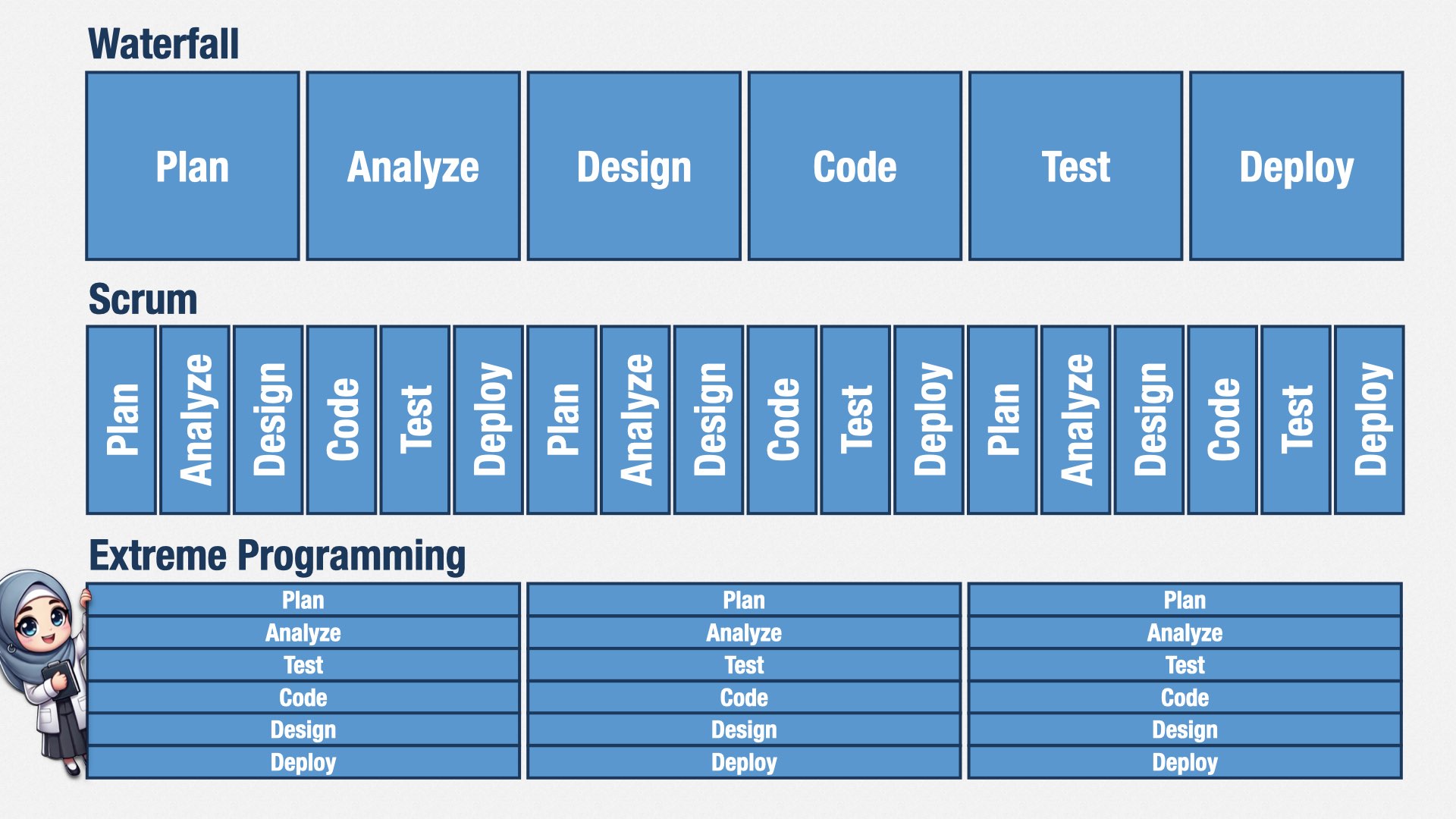
在战术层面,多数工程师并不熟悉如何“增量设计”(incremental design)。他们多半是在传统瀑布环境里学到的做法:先分析、再设计、然后才编码。
如果你把他们硬拉进 Scrum 的短迭代里,他们会创造一个个小瀑布:先一点分析,再一点设计,然后写点代码,最后测一下。如果你经常改变需求,就会导致他们的设计和测试更难做,内部质量也会下降,浪费会增多。
要在一个快速迭代、经常调整的环境里依然保持代码干净,就需要极限编程里的那套实践:演进式设计(evolutionary design)、毫不留情的重构(merciless refactoring)和测试驱动开发(TDD),把“测试、编码、设计”融为一体。如此,你就不会因为时间紧或需求变而牺牲设计和测试。
换言之,在拥有_业务_敏捷之前,必须先有_技术_敏捷。这也是我大力招聘 XP 能力的原因。
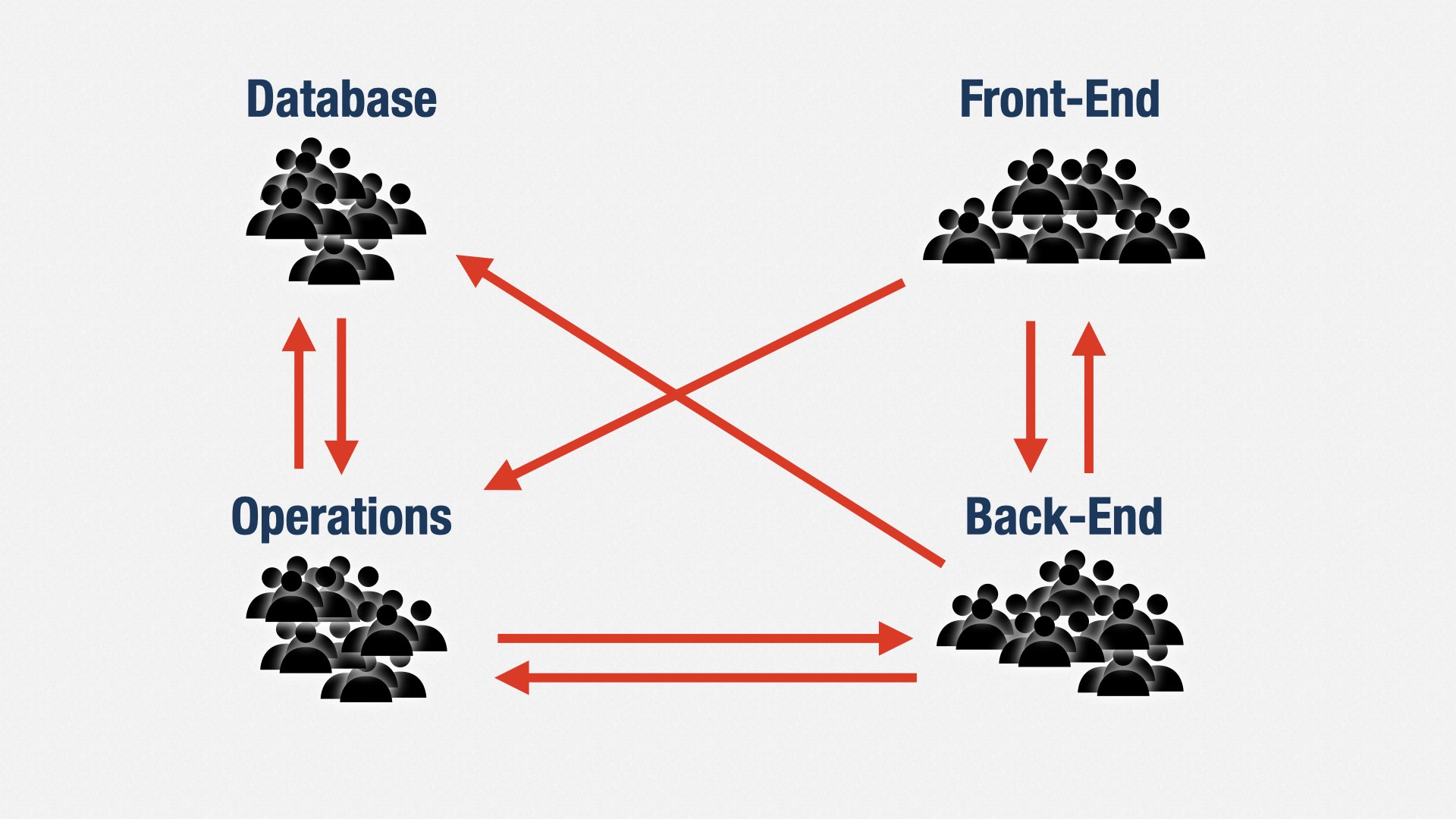
在战略层面,当业务策略变化、对不同产品投入不同时,我们也需要在组织结构上灵活应对。
传统做法是按职能分团队:前端一组、后端一组、数据库一组……需要交付价值就得协调好几拨人,延迟和错误频发,浪费大增。

敏捷团队则是跨职能的:一个团队既包含前端也包含后端、数据库、运维、安全等等。“大杂烩团队”虽然在理论上可行,但人数往往太多,就不得不拆分。现在最流行的一本书是《Team Topologies》(团队拓扑)。
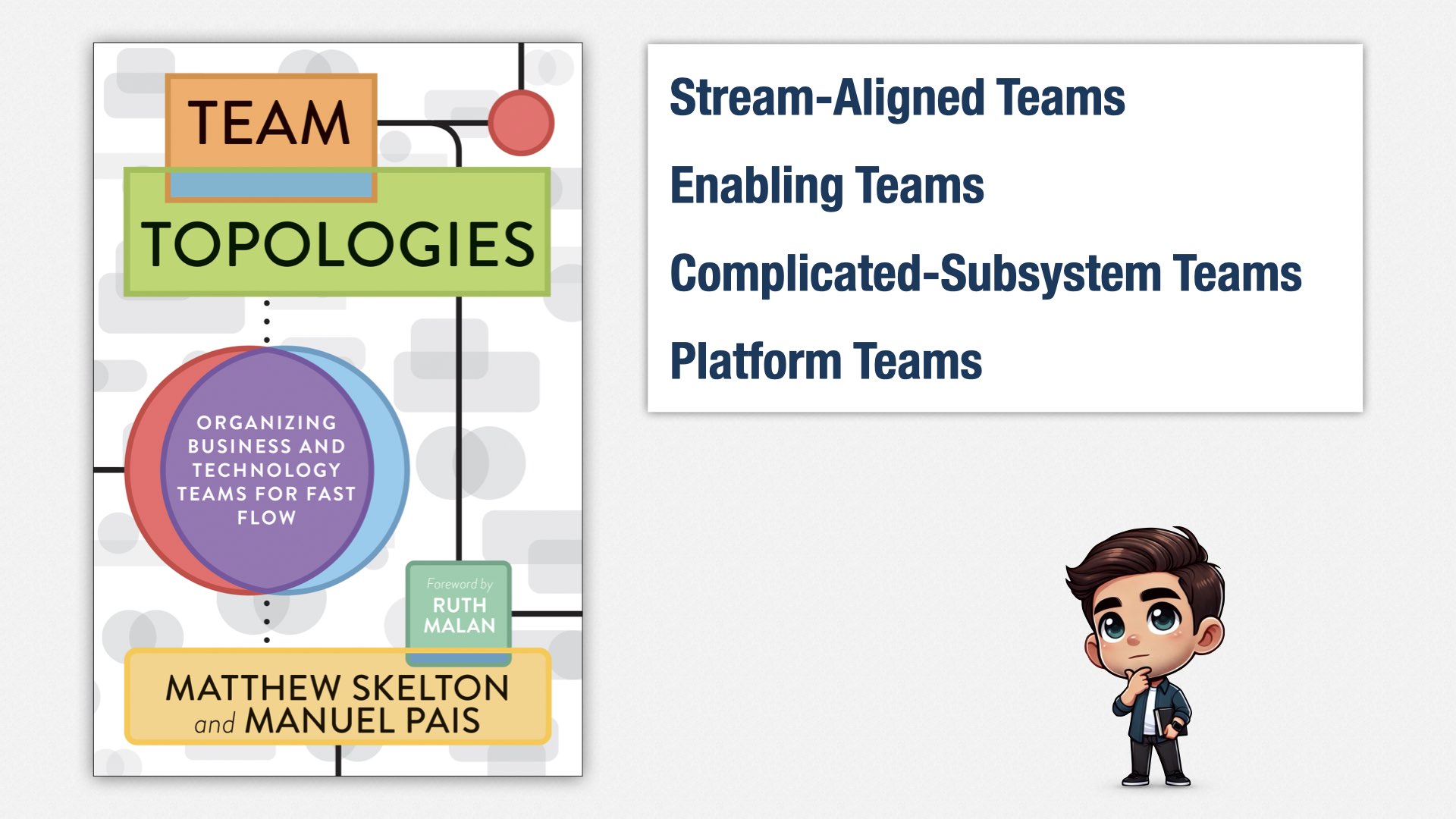
《Team Topologies》提供了一些思路,让我们在保证团队小而专(通常 7 人左右)的前提下,依然能在组织层面实现自给自足、端到端交付。
这里面包括:
流向对齐团队(Stream-aligned team):专注于交付业务价值
使能团队(Enabling team):为流向对齐团队提供帮助
复杂子系统团队(Complicated-subsystem team)
平台团队(Platform team)

假设我们有四个产品:一个旧但赚钱的、一个未来大赌注、一个市场扩张项目,以及一个更远期的赌注。可以给每个产品都组建一个独立团队。
但有时某些团队依然会变得很庞大,需要进一步拆分。
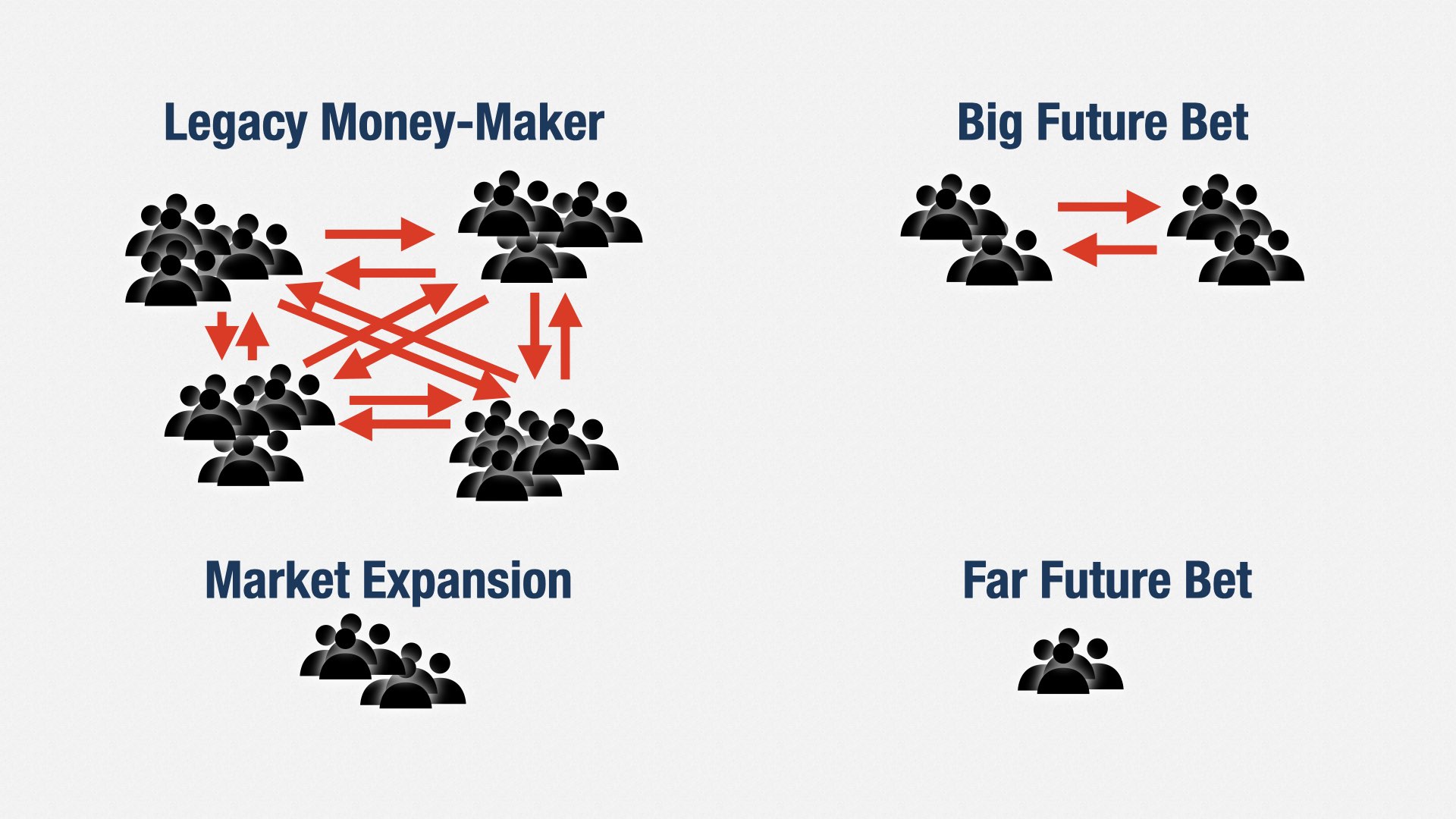
《Team Topologies》就会告诉你如何再拆分,让每个团队依然专注且自洽。
我也用过这种方式,确实还不错。

不过多年实践下来,我发现它也带来一些弊端:
团队间会形成孤岛,跨团队的项目不好推;
团队编制一旦确定,就会比较僵硬。当业务需求大变,想快速调人却要重组团队,工程部门通常会抗拒频繁重组;
像用户体验、安全、运维这类专业技能在各团队之间被“切片”分配,要么是多线并行,要么顾此失彼;
多个团队共享一堆旧代码,谁都不想管它,质量越来越差。
也就是说,需要更“向上”的做法。
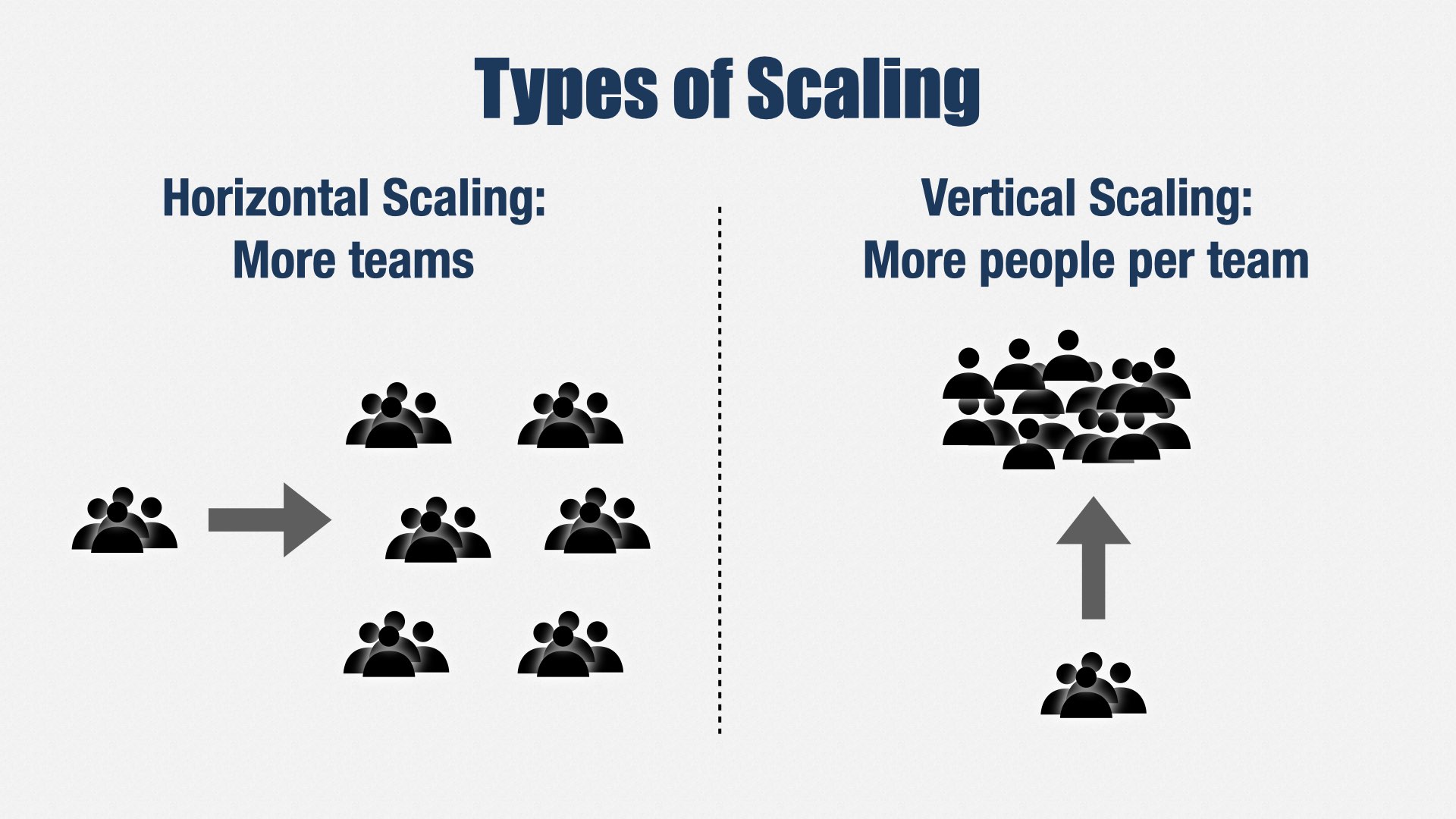
人们平时说要扩充工程团队,总是想到“增加更多团队”(水平扩张),但也有一种思路是“让现有团队变大”(垂直扩张)。
如果我们采用垂直扩张,就不必拆分成这么多小团队……
……我们可以回到“一款产品=一个团队”的理想状态。
我最喜欢的垂直扩张方案叫做 FaST。
二维码:FaST
FaST 全称是 Fluid Scaling Technology,由 Quentin Quartel 发明。你可以去 fastagile.io 了解更多,或者扫二维码看我网站上的深入介绍。今天大会的议程里也有一场关于 FaST 的演讲,主讲人是 Yoshiki Iida 和 Takeo Imai,在 C 厅 3:15 开讲!
FaST 的流程大致是:
大家定期(通常每两三天)开一个全员会(远程或现场都行)。
先有一些公共通告,然后上一轮的“Steward”(每个团队的临时负责人)汇报他们过去这两三天进展如何。
接着产品负责人更新业务优先级,展示哪些“有价值的增量”在做,哪些还没开始。如果有新变化,就说明一下为什么要改。
然后一些志愿者出来当新的“Steward”,每人带一个小团队,每个团队大约 3~5 人。Steward 说清要做什么任务,通常是上一轮没做完或新出的任务。
最后,所有人自由选择加入哪个团队,基于兴趣、技能和对公司最有利的考虑。大多数人在这期间都会留在原团队,但如果想换,也很灵活。
整个会只花 10~20 分钟,就把大团队拆成若干临时小团队,各自冲刺两三天。周而复始。
这种方式很简单,却能让一个大团队顺畅地工作,同时保持高效协作。

FaST 完全解决了我在《Team Topologies》实践中遇到的难题。我在公司也把它用在我们目前人数较多的产品团队。
小团队容易有跨团队项目;用 FaST 大家在一个大团队里,几乎不会有“跨团队”障碍。
如果业务需求大变,人可以在下一次 FaST 会议(每周两次)里马上组建新团队去实现。过程十分灵活。只需注意避免并行过多,聚焦完成已有的东西,这是我经常提醒产品经理的。
专家分配不再是难题,因为大团队里自然可以容纳各种专长,无需到处多线切换。
公共代码也不再是谁都不想管了,因为本来就是一个大团队。
FaST 并不是完美,也有一些推行上的挑战。如果你想尝试,欢迎会后找我交流或看我在网站上的演讲。只是,目前我没见过有哪种方法在规模化场景下比 FaST 做得更好。

如果我们是世界上最好的产品工程组织,我们应该主动寻找改变计划的机会、小步交付、随时根据学习到的新信息调整战略。要做到这一点,除了前面说的业务敏捷,还需要技术上的敏捷:
极限编程,让我们可以无痛地频繁改方向而不把系统搞乱;
FaST,让团队组织能灵活响应变化的业务需求。
盈利能力(Profitability)

最后一项是盈利能力。原因显而易见:如果我们想持续照顾好员工、用户和所有利益相关者,那前提是公司能存活下去。仅仅构建出好软件还不够,还要能卖得出去、成本可控,能在生产环境顺利运转。
有个有趣的现象:工程实力并不总和业务成功正相关。我过去做了 23 年咨询,见到不少技术上很糟糕但商业上很成功的公司,因为他们满足了市场需求。
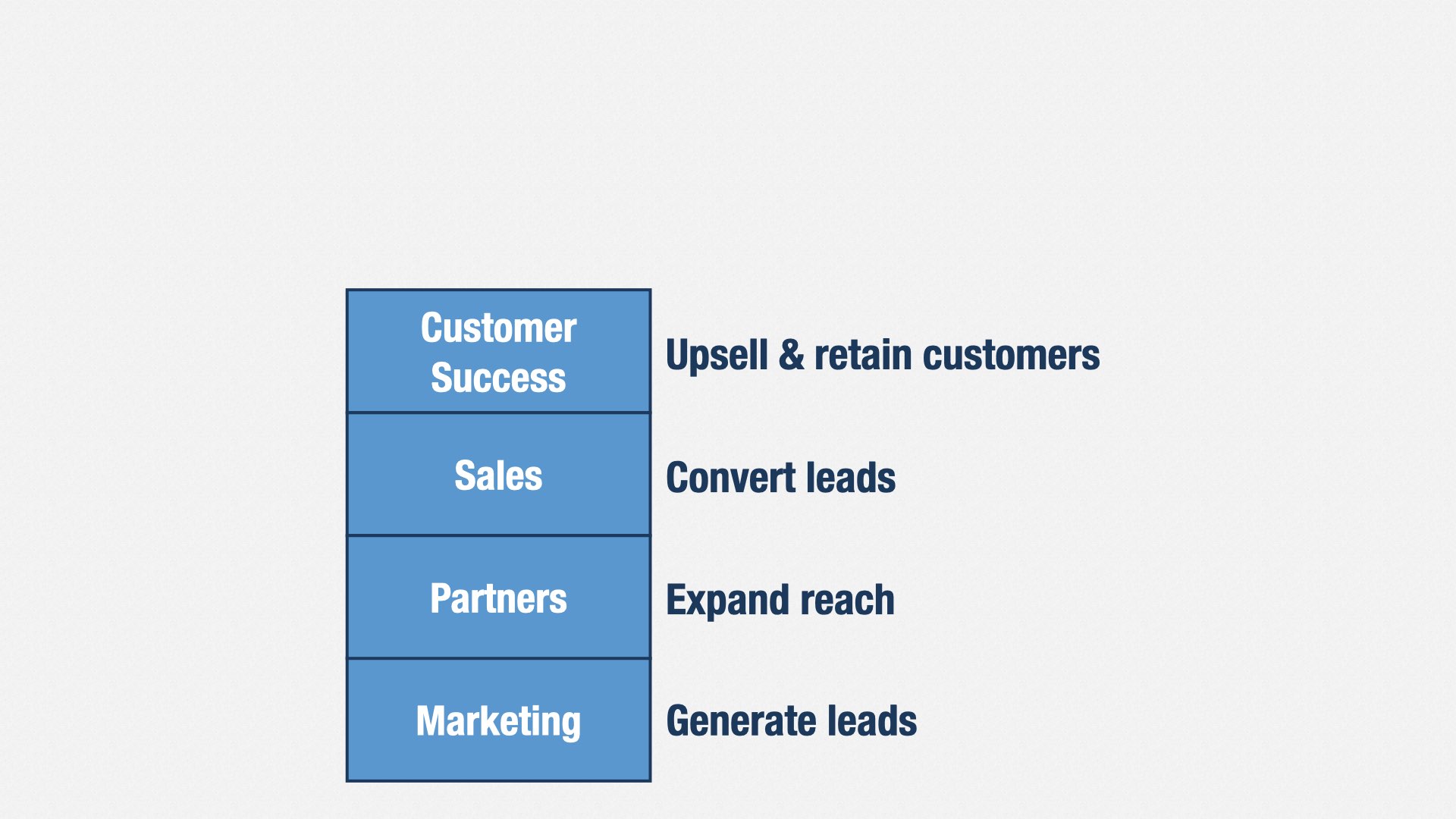
比如在 B2B 领域:
营销要带来潜在客户(leads),看“转化率”;
合作伙伴(Partners)也会带来潜在客户或直接成单;
销售要把这些潜在客户变成付费用户;
客户成功(Customer Success)要留住用户并促成增购;
那产品工程部门是干什么的?
[停顿]
答案是:创造新的增长机会。假设公司每年自然增长 1000 万美元收入,我们要让这个增长变成 1200 万、1500 万、甚至 2000 万。我们推出的新功能就该帮助公司切入新市场、抓住更多客户、让销售更容易签单、让现有客户更满意,从而加速业务增长。
我们的产品特性应能打开新市场,让营销带来更多潜客;
给合作伙伴提供好用的 API,让他们为我们拉来更多销量;
跟上市场需求,让销售更容易成单;
修复客户的痛点,让客户留存率和增购率更高。
总之,你在工程上投下的每一块钱,最后都应该转化成公司的“永久价值提升”。也许这价值不一定是金钱,也可能是拯救疟疾患者或对抗气候变化。但无论何种定义,“产品工程”的目标就是改变组织的价值创造曲线,让它更高、更快。

如果我们是世界上最好的产品工程组织,我们就会_为销售而构建产品_。我们会与内部各部门紧密合作,把我们的软件打造得适合真实世界中的营销、销售、内容、支持、合作伙伴、财务以及业务运营等各方面需求。同时,我们会时刻考虑可靠性、可观测性、安全性和可运营性,用软件来真正改变公司业务增长曲线。
而这一切要靠拥有最优秀的人才;靠高水平的内部质量,让变更轻松、bug 稀少;靠关注最能打动用户与客户的需求;靠让内部利益相关者信任我们的决策;靠不断挖掘新机会、不断调整战略。
我们现在还不是世界上最好的产品工程组织。但我们希望成为,并且会永不停歇地改进。
希望这些思路能帮助你的公司也不断前进。感谢大家的聆听!