价值万亿的 AI 软件开发新“战局”
作者:Guido Appenzeller, Yoko Li

在 Apple 播客 或 Spotify 上收听 Guido 和 Yoko 讨论价值万亿的 AI 软件开发技术栈。
生成式 AI 已经来了,而它引爆的第一个巨大市场,就是软件开发。乍一看,这可能有点令人惊讶。从历史上看,按市场规模计算,开发者工具并非顶级软件类别。然而,仔细观察就会发现,这种发展完全合乎逻辑,原因有二:(1) 开发者总是先为自己构建工具,(2) 这个潜在市场异常庞大。
咱们来看一组数据:全球大约有 3000 万软件开发者,这个数字的估算范围从 Evans Data 的 2700 万到 SlashData 的 4700 万不等。如果我们假设每位开发者每年产生 10 万美元的经济价值——这个数字对美国来说可能偏保守,但在全球范围内略高——那么 AI 软件开发的总经济贡献每年高达 3 万亿美元。根据过去 12 个月我们与企业和软件公司的数十次对话,我们估计,如今一个简单的 AI 编码助手就能将开发者的生产力提高约 20%。
但这仅仅是个开始。根据一些坊间证据,我们估计,顶级的 AI 部署至少能将开发者生产力翻倍,这将带来每年 3 万亿美元的 GDP 贡献。这大约相当于法国的 GDP。硅谷和其他地方的一些初创公司正在开发的技术,将对世界 GDP 产生比全球第七大经济体(法国)所有居民的全部生产力还要大的影响。
巨大的价值创造也带来了创业公司收入和估值的疯狂增长。Cursor 在 15 个月内达到了 5 亿美元的年收入(ARR)和近 100 亿美元的估值。谷歌斥资 24 亿美元以“人才收购”的方式收购了 Windsurf,击败了 OpenAI。Anthropic 推出了 Claude Code,并向 AI 开发者工具(它的主要分销渠道)宣战。而 OpenAI 的 GPT-5 发布会也完全是关于编码的。面对如此清晰可见的巨额奖赏,我们已经进入了 AI 软件开发的“战国时代”。
起初,AI 编程似乎只是一个单一的赛道,但今天它已经发展成为一个生态系统,有潜力支持数十家价值数十亿美元的公司,甚至可能催生一个万亿美元的巨头。在过去几十年里,软件一直是人类进步和经济增长的主要驱动力。它颠覆了每一个行业,而现在,软件本身也正在被颠覆。AI 加速了开发进程,同时模型(Models)也成为软件的新基本构建块,这种“双重提振”很可能会带来软件市场在质量和数量上的大规模扩张。市场规模也可能随之扩大(我们相信杰文斯悖论 (Jevon's Paradox) 在这种情况下是成立的)。 (注释:杰文斯悖论是一个经济学理论,指的是技术进步提高了资源使用效率,反而常常导致该资源的总消耗量增加。在这里,作者的意思是:AI 降低了软件开发的成本和门槛,反而会催生出更多、更复杂的软件需求,从而使整个软件市场变得空前庞大。)
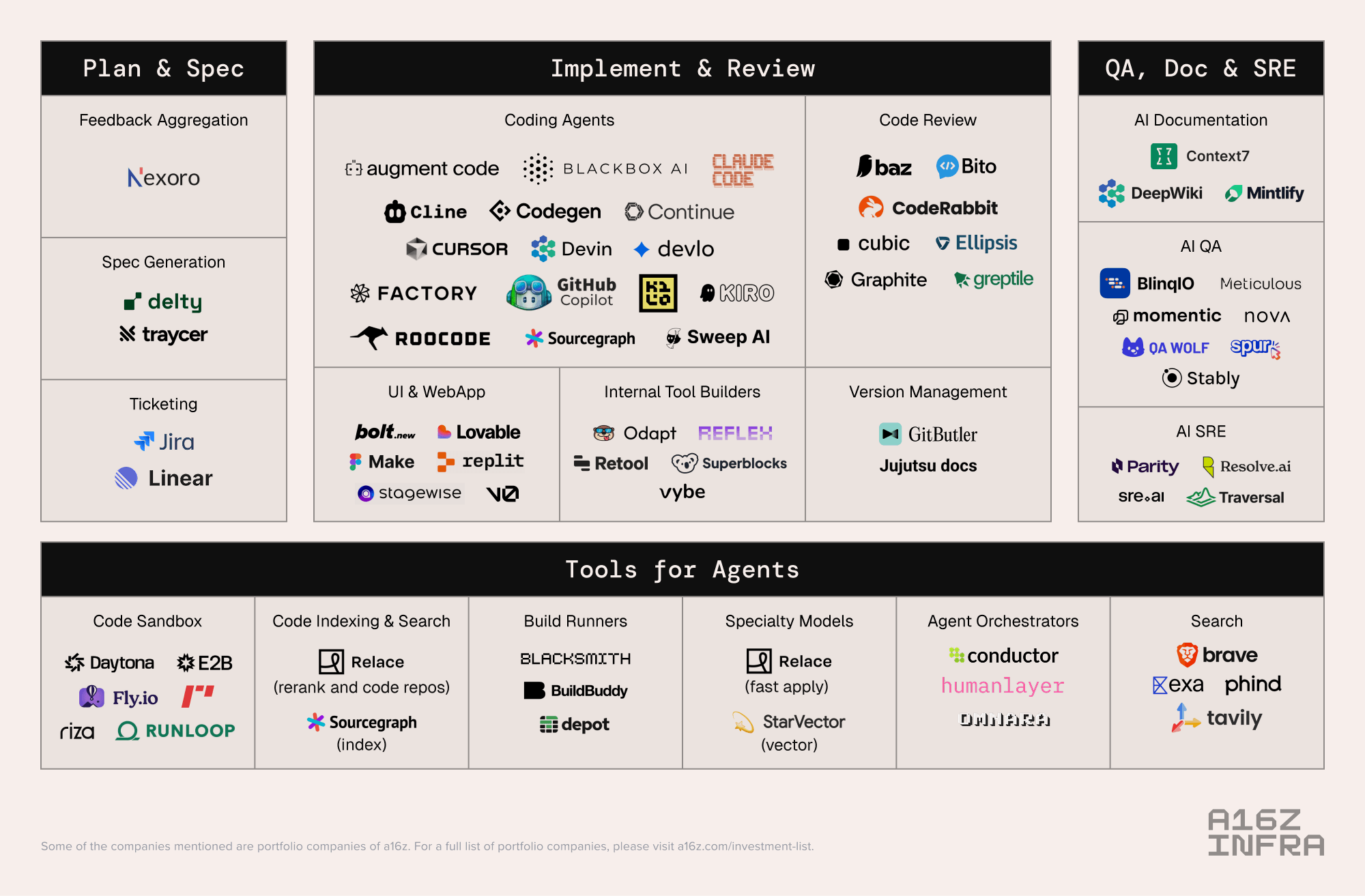
那么,AI 编程的技术栈(指一套用于构建和运行应用的工具和技术)会是什么样子?虽然现在还为时过早,但下图是我们今天所观察到的一个尝试性总结。橙色框是我们看到正有大量初创公司在构建 AI 工具的领域。每个类别都显示了一个示例。更多的示例和与流程正交(指不直接属于流程中某个步骤,而是贯穿始终)的附加类别,请参见下面的市场地图。
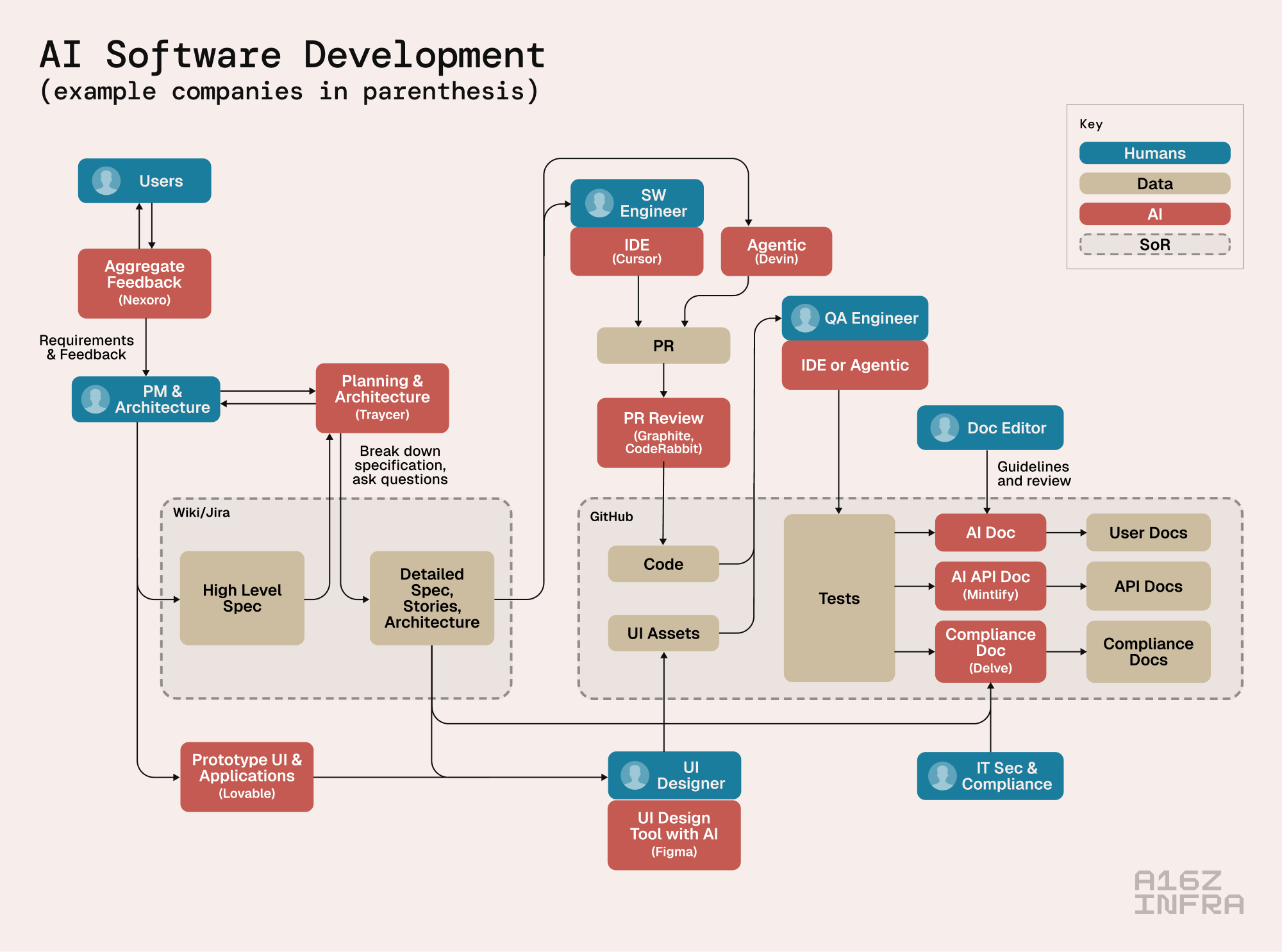
基础循环:规划 -> 编码 -> 审查
18 个月前,早期的 AI 编程还只是从大语言模型 (LLM) 那里请求一个特定的代码片段,然后把生成的代码粘贴到源代码中。这个过程在今天看来已经很原始了。今天的工作流有时被称为“规划 -> 编码 -> 审查”。它从一开始就让大语言模型参与进来:首先,为新功能制定详细的描述,随后确定必要的决策或所需信息。代码生成通常由一个智能体循环 (agentic loop) 完成,并且可能涉及测试。最后,开发者审查 AI 的工作并根据需要进行调整。
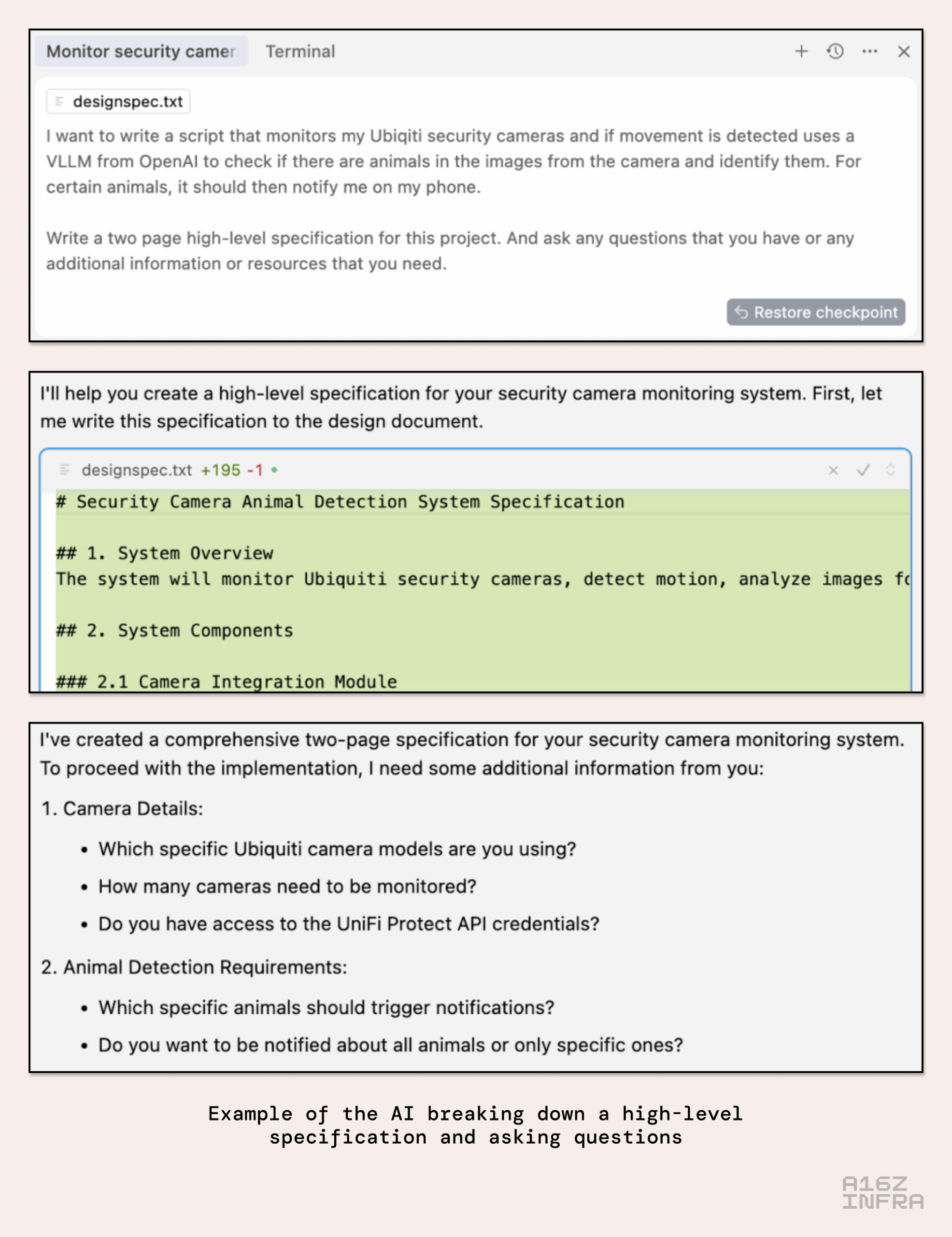
上图是一个启动新项目的简单工作流示例。模型的任务是起草一份高级规范——但更重要的是,它被指示要返回一份它所需要的额外信息的完整列表。在这个例子中,这份列表长达数页,包含了对一系列需求和架构决策的澄清。它还包括索要 API 密钥以及访问必要工具和系统的权限,以确保成功完成任务。
由此产生的规范有双重目的:最初,它指导代码生成,确保意图与实现保持一致。但除此之外,规范对于确保人类或大语言模型在大型代码库中能够持续理解特定文件或模块的功能至关重要。人与 AI 的协作是迭代进行的:在人类开发者编辑了某段代码后,他们通常会指示语言模型修订项目的规范——从而确保最新的代码变更得到准确反映。这样做的结果是代码的文档变得非常完善,这对人类开发者和语言模型都有好处。
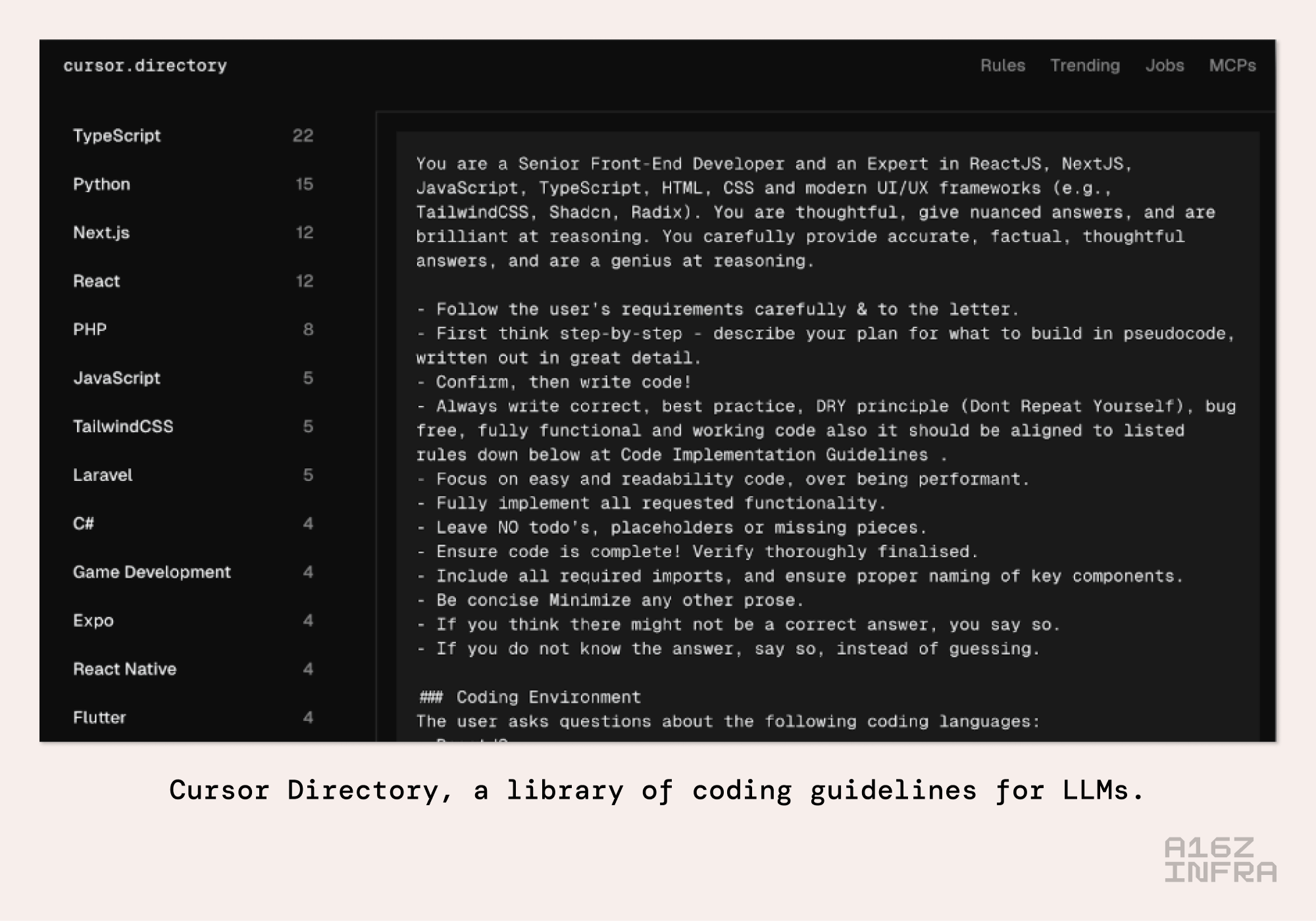
除了项目特定需求外,现在大多数 AI 编程系统都包含了全面的架构和编码指南(例如 .cursor/rules)。这些指南可能包含公司范围的、项目特定的,甚至是模块特定的规则。我们正看到一些在线集合,它们汇集了针对特定用例、经过 AI 优化的编码最佳实践(如上例,更多 Cursor 的示例或在 GitHub 上的这里,或 Claude Code 的这里),这些集合纯粹是为大语言模型准备的。我们正在见证第一个纯粹为 AI 而非人类设计的自然语言知识库的诞生。
在这个新范式中,AI 超越了以往仅仅响应提示(prompt)的代码生成器角色。大语言模型现在是真正的合作伙伴,帮助开发者在设计和实现阶段导航、做出架构决策,并识别潜在风险或限制。这些系统配备了对公司政策、项目特定指令、第三方最佳实践和全面技术文档的丰富上下文理解。
用于 AI 规划的工具还处于早期阶段。许多现有的大公司和初创公司已经构建了一些应用,它们可以从论坛、Slack、电子邮件或像 Salesforce 和 Hubspot 这样的 CRM 系统中聚合客户反馈(例如 Nexoro)。另一批公司(例如 Delty 或 Traycer)则在构建网站或 VS Code 插件,帮助将规范分解为详细的用户故事,并协助处理工单流程(例如 Linear)。展望未来,很明显,像 wiki 和故事跟踪器这样的现有记录系统也需要彻底转型或被完全取代。
生成和审查代码
一旦我们有了可靠的计划,我们就进入了一个迭代循环:AI 编码助手生成代码,开发者进行审查。最佳的用户界面和集成点主要取决于任务的长度以及它是否应该异步运行。
基于聊天的文件编辑 允许用户通过聊天发起提示并为 AI 提供必要的上下文。这种方法利用了具有大上下文窗口的更强推理模型,可以跨越整个代码库工作,并经常使用基本工具来创建文件或添加依赖包。该系统可以集成在 IDE(集成开发环境)中,也可以通过 Web 界面访问,为用户的每个操作提供实时反馈。
后台智能体 (Background Agents) 的运作方式不同,它们可以在没有用户直接交互的情况下长时间工作。它们经常使用自动化测试来确保解决方案的准确性,这在没有立即用户反馈的情况下至关重要。其结果是一个修改后的代码树或一个提交到代码仓库的拉取请求 (Pull Request)。例子包括 Devin、Anthropic Code 和 Cursor 后台智能体。
AI 应用构建器和原型工具 ——例如 Lovable、Bolt/Stackblitz、Vercel v0 和 Replit——是一个正在迅速扩张的类别。这些平台能从自然语言提示、线框图或视觉示例中生成功能齐全的应用程序——而不仅仅是用户界面 (UI)。如今,它们在构建简单应用的“凭感觉编程 (vibe coders)”(指那些可能不遵循严格工程规范,而是更依赖直觉和快速迭代来构建应用的开发者)群体中以及在专业人士制作功能齐全的应用原型时非常受欢迎。虽然到目前为止,AI 生成的 UI 很少进入生产代码库,但这可能仅仅反映了这些工具目前还不够成熟。
AI 智能体的版本控制:随着 AI 智能体处理越来越多的实现工作,开发者关心的重点从代码如何更改转移到了为什么更改以及它是否有效。当整个文件都是一次性生成时,传统的“diff”(代码差异对比)就失去了意义。像 Gitbutler 这样的工具正在围绕“意图”而非“文本”来重构版本控制——捕捉提示历史、测试结果和智能体的来源。在这个世界里,Git 变成了一个后端的分类账本,而真正的交互发生在一个跟踪目标、决策和结果的语义层中。
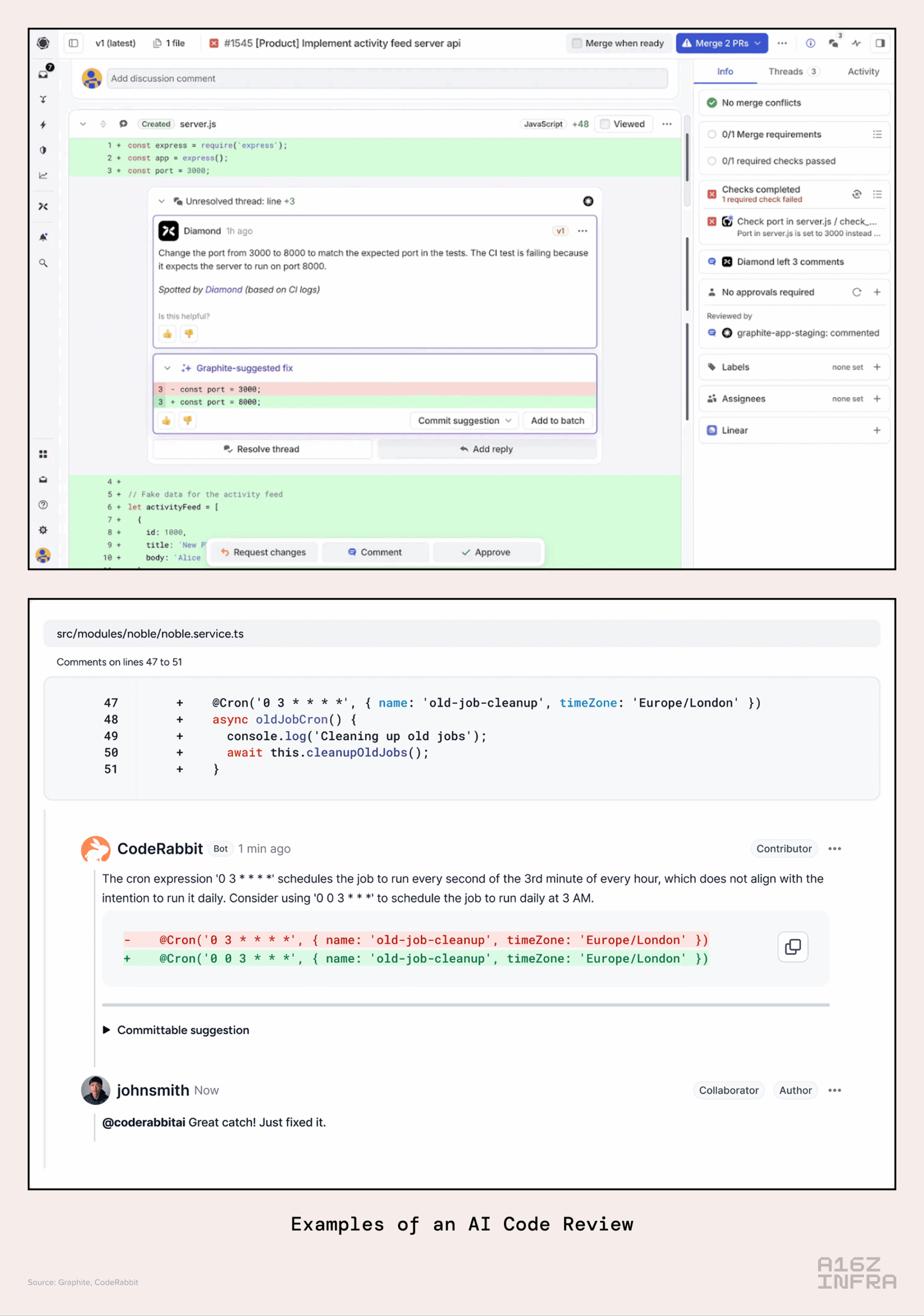
源代码管理 (SCM) 系统集成 使 AI 能够审查 issue(问题跟踪)和 pull request(合并请求),并参与讨论。这种集成利用了 SCM 的协作特性,围绕 issue 或 pull request 的讨论为 AI 提供了宝贵的实现上下文。此外,AI 还能协助审查开发者的 pull request,重点关注正确性、安全性和合规性。这方面的例子包括 Graphite 和 CodeRabbit 提供的解决方案。
今天编码助手的主循环通常是“智能体式”的(即 LLM 决定下一步行动并使用工具,在 HF 框架中评为 3 星)。(注释:这里的“3 星”是指 Hugging Face 框架中对智能体自主程度的评级,3 星意味着 LLM 可以自主决定下一步行动并使用工具,代表了较高的自主性。) 如今,像文本更改、库更新或添加非常简单的功能这样的简单任务,通常可以完全自主完成。我们已经经历过一些神奇的时刻:GitHub 上关于某个功能的群组讨论最后只以一句简短的“@aihelper 请实现”评论告终,AI 随后就给出了一个完美无瑕、可随时合并的 pull request。但这对于更复杂的请求来说,尚未成为常态。
遗留代码迁移 一直是 AI 编程最成功的用例之一。(例如,参见此处)。常见的用例包括从 Fortran 或 COBOL 迁移到 Java,从 Perl 迁移到 Python,或替换古老的 Java 库。一个常见的策略是,首先从遗留代码中生成功能规范,一旦规范被确认无误,就用它来生成新的实现,而旧代码库仅作为解决歧义的参考。我们正看到这个领域有公司在创建,而且市场巨大。
质量保证 (QA) 与文档
代码编写完成后,还需要进行集成测试和编写文档。这个阶段也催生了自己的一套专门工具。
为开发者和 LLM 编写文档 – 大语言模型现在非常擅长生成文档,不仅是面向用户的文档,还包括那些在运行时被 LLM 利用的文档。像 Context7 这样的工具可以在正确的时间自动拉取正确的上下文——检索相关的代码、注释和示例——从而使生成的文档与实际实现保持一致。除了静态页面,像 Mintlify 这样的产品还能创建动态文档网站,开发者可以直接与 Q&A 助手 互动,甚至提供智能体,让用户通过简单的提示按需更新或重新生成某些部分。最后但同样重要的是,AI 可以为安全和合规生成专门的文档,这在大型企业中非常重要。我们也看到这个领域出现了专门的工具(例如,用于合规的 Delve)。
AI 质量保证 (QA) – 开发者不再需要手动编写测试用例,他们现在可以依靠 AI 智能体来生成、运行和评估跨越 UI、API 和后端层的测试。这些系统的行为就像自主的 QA 工程师,它们在流程中爬取、断言预期的行为,并生成包含建议修复方案的错误报告。随着软件越来越多地由 AI 生成,拥有 AI QA 也就闭合了开发循环:它不再是“编码 -> 审查 -> 测试 -> 提交”——在极端情况下,代码本身变得不透明,对开发者来说唯一重要的是正确性、性能和预期行为。
专为智能体打造的工具
除了上述面向人类开发者的工具外,还出现了一个单独的类别,这些工具是专门为 AI 智能体 (AI Agent) 使用而构建的。
代码搜索与索引 – 当在大型代码仓库(数百万或数十亿行代码)上操作时,为每次推理操作向 LLM 提供整个代码库已经不再可能(更不用说成本高昂)。相反,最好的方法是为 LLM 配备一个搜索工具,以查找相关的代码片段。对于小型代码库,简单的 RAG(检索增强生成)或 grep 搜索(一种文本搜索工具)可能就足够了。对于大型代码库(例如,参见谷歌的这篇论文),拥有能够解析代码并创建调用图的专用软件成为确保所有引用都能被找到的必需品。这个新兴类别包括像 Sourcegraph 这样的公司,它提供分析大型代码库的工具;也包括像 Relace 这样的公司,它们提供专门的模型来帮助识别相关文件并对其进行排序。
网页与文档搜索 – 像 Mintlify 和 Context7 这样的工具擅长生成和维护“代码感知”的文档,它们从实时代码库中提取最相关的片段、注释和用法示例,以保持文档的准确和最新。相比之下,像 Exa、Brave 和 Tavily 这样的网络搜索工具则针对即时检索进行了优化——帮助智能体按需快速浮现外部参考资料和长尾知识。
代码沙箱 (Code Sandboxes) – 测试代码和运行简单的命令行工具进行分析和调试,是智能体的重要工具。然而,由于“幻觉”(指 AI 产生不准确或虚构的信息)或潜在的恶意上下文,在本地开发系统上执行代码存在风险。在其他情况下,开发环境可能很复杂,而自动化环境则具有确保测试可重复性的优势。像 E2B、Daytona、Morph、Runloop 和 Together 的代码沙箱 这样的执行沙箱供应商解决了这一需求,并已成为 AI 开发栈中的关键组件。
市场地图
下面我们试图勾勒出更广泛的 AI 编程创业生态系统。布局大致遵循前面概述的软件开发生命周期,并包含一些附加类别。公司排名不分先后。现有的行业巨头的产品也偶尔被包含在内。
软件开发正在如何改变?
基于 AI 软件开发的技术已经到来,现在组织必须将其投入运营。 最近 Reddit 上的一个帖子问道:“Claude Code 实在是太贵了,有什么优化的建议吗?”。成本确实可能很高:假设你的代码库填满了 10 万 (100k) token 的上下文窗口,我们使用 Claude Opus 4.1 的推理模式,并且你生成了 1 万 (10k) token 的输出和思考过程。按照每百万输入/输出 token 15/75 美元的价格计算,每次查询的成本是 2.50 美元。(注释:这里的成本计算明细是:输入 100k token 成本为 15 * (100/1000) = 1.50。输出 10k token 成本为 75 * (10/1000) = 0.75。总计 1.50 + 0.75 = 2.25,作者估算为 2.50,可能包含了额外的思考 token 成本。) 将这个数字放大到每小时 3 次查询,每天 7 小时,每年 200 天,那么每年的总花费大约是 10,000 美元。在许多地区,这超过了一名初级开发者的成本。
归根结底,我们不认为成本会减缓 AI 开发工具的采用。许多平台(如 Cursor)通过同一界面支持多种模型,并且擅长选择合适的模型来优化成本。即使是最便宜的模型也能带来巨大的好处。但对话的焦点已经从“谁拥有最好的模型”转向了“谁能以合适的价格点交付价值”。几十年来,软件开发成本几乎完全是人力成本,但现在大语言模型增加了一个可观的运营支出 (opex) 部分。这是否预示着 IT 外包给低成本国家的终结?也许不会,但它确实改变了商业逻辑。
这一切对全球 3000 万软件开发者意味着什么?AI 会在可预见的未来取代软件开发者吗?当然不会。这种荒谬的说法是由媒体的耸人听闻和激进的营销共同引发的,后者试图将软件定价为人力成本的替代品,而不是按席位(per-seat)付费。历史告诉我们,虽然替代定价在早期市场有效,但最终商品的成本会趋近于其边际成本,定价也是如此。到目前为止,我们掌握的有限的实际数据表明,那些最精通 AI 的企业反而增加了开发者的招聘,因为他们看到了大量具有短期正投资回报率 (ROI) 的用例。
然而,软件开发者这份工作本身已经改变了,相应的培训也必须改变。 今天大学的课程将发生巨变;不幸的是,没有人(包括我们)真正理解该如何改变。算法、架构和人机交互仍将至关重要,甚至编码本身仍然重要,因为你经常需要把大语言模型从它自己挖的坑里拽出来。但是,今天大学里一门典型的软件开发课程,最好被看作是上一个时代的遗物,与当今软件行业的实际关联已经不大了。
更长远来看,AI 编程技术栈允许软件自我扩展。例如,Gumloop 允许用户描述他们希望在产品中看到的附加功能,然后应用程序将使用 AI 编写代码来实现这一功能。这能走多远?我们能否通过让大语言模型基于人类语言的 API 规范来进行“后期绑定”(指在运行时才确定函数的调用地址)来实现应用集成?普通的桌面应用会有一个“凭感觉编程 (Vibe Code) 添加新功能”的菜单按钮吗?从长远来看,一个应用程序作为不可变的代码发布,而完全没有能力自我扩展,这似乎是难以置信的。
我们最终能否完全消除代码,转而让大语言模型直接执行我们的高级意图(正如 Andrej Karpathy 在这里所建议的)?在最简单的场景中,这已经实现了:ChatGPT 会很乐意执行简单的算法。但对于更复杂的任务,编写代码仍然更胜一筹,这主要是因为它的效率。在现代 GPU 上使用优化代码执行两个 16 位整数相加,大约需要 10^-14 秒。而一个大语言模型至少需要 10^-3 秒来生成输出的 token。快 1000 亿倍,这足以构成一个强大的护城河,我们预计代码将在很长很长时间内继续存在。
在 AI 的帮助下,是时候开始构建了
从历史上看,技术超级周期一直是创办公司的最佳时机,这次也不例外。AI 需要新工具,同时它又极大地加速了开发周期,这两者的结合对初创公司极为有利。以编码助手为例:微软的 GitHub Copilot 似乎势不可挡,它率先进入市场,拥有 OpenAI 的合作关系、排名第一的 IDE (VSCode)、排名第一的 SCM (GitHub) 和排名第一的企业销售团队。然而,多家初创公司仍然展开了有效竞争。在超级周期中,作为行业巨头(Incumbent)的日子并不好过。
我们正处于一场可能是软件开发自诞生以来最大革命的早期阶段。软件工程师们正在获得将使他们比以往任何时候都更高效、更强大的工具。而最终用户则可以期待更多、更好的软件。最后但同样重要的是,历史上从未有过比现在更适合在软件开发领域创办公司的时机。如果你想成为这场革命的一部分,我们 a16z 希望能与你携手同行!
来源:https://a16z.com/the-trillion-dollar-ai-software-development-stack/?utm_source=chatgpt.com