如何加速大语言模型的运行 [译]
Theia Vogel
在我上一篇文章中,我亲自动手构建了一个 Transformer。在那篇文章里,我们采用了典型的自回归式采样方法,具体来说就是这样:
def generate(prompt: str, tokens_to_generate: int) -> str:tokens = tokenize(prompt)for i in range(tokens_to_generate):next_token = model(tokens)tokens.append(next_token)return detokenize(tokens)
这种推理方法不仅优雅,而且深刻体现了大语言模型(LLM)的核心机制——它们是自回归的,即使用自己产生的输出作为下一步的输入。虽然对我们只有几千个参数的简易模型而言,这种方法运行得很好。但遗憾的是,对于实际应用中的模型来说,这个方法速度太慢了1。那么,问题出在哪里,我们又该如何提高其速度呢?
本文是一篇综合性的调研文章,涵盖了多种提升大语言模型运行速度的方法,从改善硬件利用效率到巧妙的解码技巧应有尽有。虽然这篇文章并非面面俱到,也不是每个话题的深度解析,毕竟我不是这些领域的全部专家。但我希望你能从中找到一些有用的信息,作为深入了解你感兴趣话题的起点。(我也尽量提供了相关论文和博客文章的链接。)
简单的推理过程为何效率低下?
使用基本自回归的 generate 函数进行简单推理之所以效率低下,主要原因有两个:算法和硬件。
从算法角度看,generate 每个循环需要处理越来越多的 Token(词元),因为我们每个循环都会向上下文添加一个新 Token。这就意味着,若要从一个含有 10 个 Token 的提示中生成 100 个 Token,你需要在不仅仅是 109 个 Token 上运行 model。你实际上需要处理 10 + 11 + 12 + 13 + ... + 109 = 5,950 个 Token!(最初的提示可以并行处理,这也解释了为什么在推理 API 中提示 Token 的成本通常较低。)因此,随着生成过程的进行,模型的速度会逐渐降低,因为每次生成新 Token 时,都要处理更长的前缀:
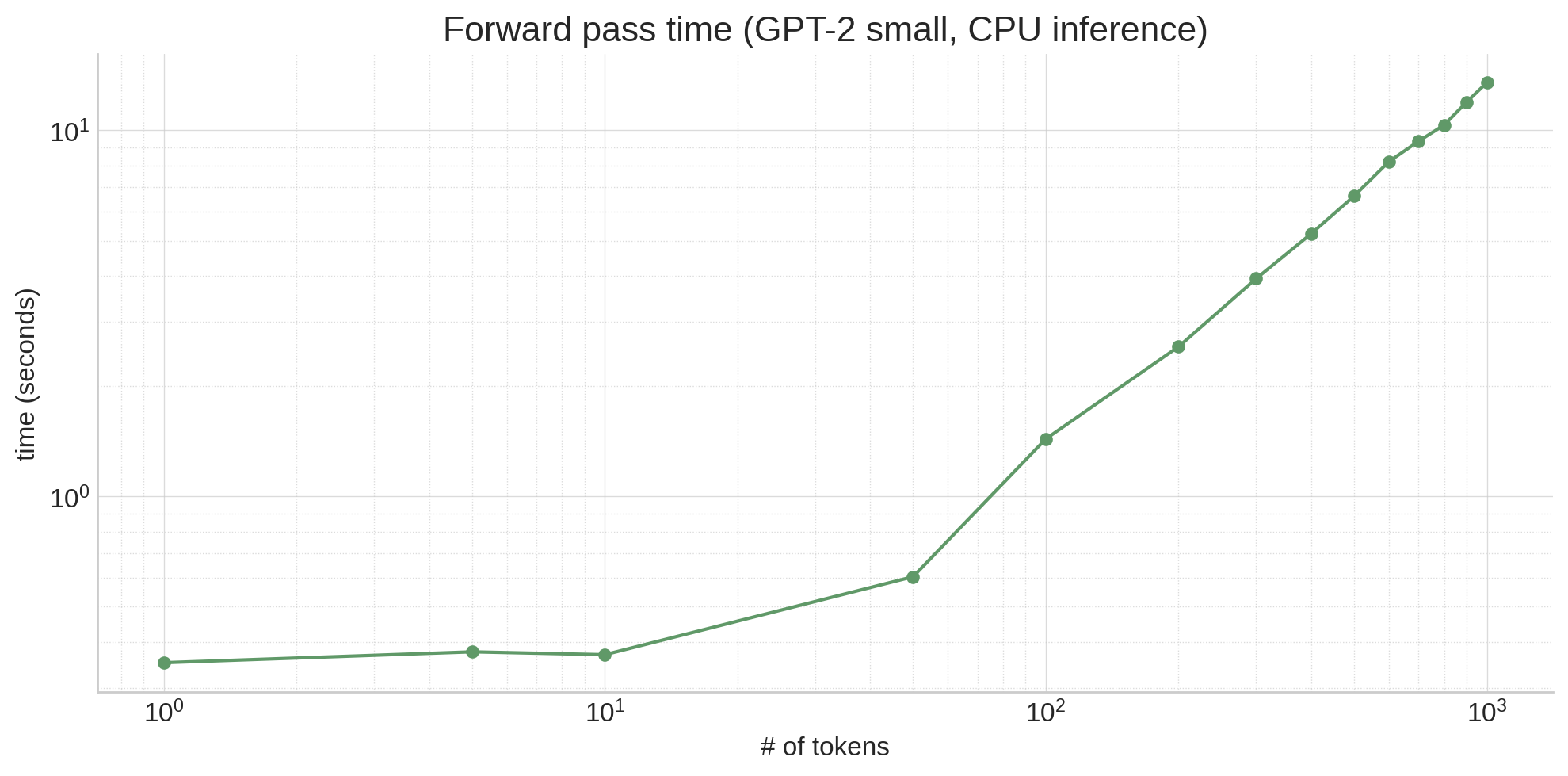
至少在普通的注意力机制中,算法是二次方的:所有 Token 都关注所有其他 Token,这导致了 N² 级别的复杂度增长,进一步加剧了问题。
那么硬件原因是什么呢?原因很简单:大语言模型(LLM)本身体积巨大。哪怕是像 gpt2 这样的相对较小的模型(1.17 亿参数),也有数百兆字节的大小,所有这些数据都必须存储在 RAM 中。RAM 的速度很慢,现代处理器(包括 CPU 和 GPU)通过在处理器附近设置更快速的缓存来补偿这一不足2。尽管处理器的类型和型号不同,细节也各有区别,但大致来说,LLM 的权重并不能完全存放在缓存中,因此大量时间被用于等待从 RAM 加载权重。这就导致了一些反直觉的现象!例如,从上图可以看到,处理 10 个 Token 的速度并不比处理单个 Token 慢太多,尽管激活张量的体积增加了 10 倍,这是因为主要的时间消耗在于移动模型权重,而不是计算过程本身!
指标
在讨论大语言模型 (LLM) 推理速度时,我们通常关注以下几个关键指标:
- 首个 Token 响应时间 - 从收到输入到输出第一个 Token 所需的时间有多长?
- 整体生成延迟 - 从收到输入到完成最终 Token 输出的时间长度是多少?
- 吞吐量 - 系统能同时处理多少个独立的生成任务?
- 硬件利用效率 - 我们对计算资源、内存带宽及其他硬件功能的利用程度如何?
这些指标受到不同优化措施的影响。例如,进行批量处理可以提高吞吐量并更有效地利用硬件资源,但可能会导致首个 Token 响应时间和整体生成延迟的增加。
硬件
提升推理速度的一个直接方法是采用更高性能的硬件。如果有足够的资金支持,你可以选择购买更先进的设备,或者在预算有限的情况下,更充分地利用现有的硬件资源。
在选择升级硬件时,通常会考虑购买加速器,比如 GPU,或者对于像 Google 这样的公司,可能是 TPU。
使用加速器可以显著提高处理速度,但需要注意的是,CPU 和加速器之间的数据传输可能会成为瓶颈。如果模型无法完全装入加速器的内存中,那么在前向传递过程中,模型可能需要频繁在内存与加速器之间交换,这会大幅降低运行速度。苹果的 M1/M2/M3 芯片之所以在推理性能上表现出色,部分原因是它们实现了 CPU 与 GPU 的统一内存管理。
在使用 CPU 或加速器进行推理时,还需要考虑是否充分发挥了硬件的潜能。经过良好优化的程序能够从性能较低的硬件中挤出更多效能,而未经优化的程序即使在顶级硬件上也可能表现平平。
举个例子,在 PyTorch 中,你可以使用 F.softmax(q @ k.T / sqrt(k.size(-1)) + mask) @ v 来实现注意力机制,这样可以得到正确的结果。但如果改用 torch.nn.functional.scaled_dot_product_attention,当 FlashAttention 可用时,它会将计算任务委派给它,利用专门编写的内核更有效地使用缓存,从而实现高达 3 倍的加速。
编译器 (Compilers)
一个更普遍的例子是像 torch.compile、TinyGrad 和 ONNX 这样的编译器,它们能够将简单的 Python 代码转换成针对特定硬件进行优化的执行代码。例如,我可以这样编写一个函数:
def foo(x):s = torch.sin(x)c = torch.cos(x)return s + c
直接来看,这个函数需要执行以下步骤:
- 为变量
s分配与x.shape()相同大小的内存 - 遍历
x的每个元素,计算其sin值 - 为变量
c再分配一个与x.shape()相同大小的内存 - 再次遍历
x的每个元素,计算其cos值 - 为最终的结果张量分配与
x.shape()相同大小的内存 - 遍历
s和c,将它们的值相加得到最终结果
这些步骤中的每一个都相对缓慢,尤其是当涉及到 Python 与原生代码之间的交互时。那么,如果我使用 torch.compile 来编译这个函数会怎样呢?
>>> compiled_foo = torch.compile(foo, options={"trace.enabled": True, "trace.graph_diagram": True})>>> # call with an arbitrary value to trigger JIT>>> compiled_foo(torch.tensor(range(10)))Writing FX graph to file: .../graph_diagram.svg[2023-11-25 17:31:09,833] [6/0] torch._inductor.debug: [WARNING] model__24_inference_60 debug trace: /tmp/...zfa7e2jl.debugtensor([ 1.0000, 1.3818, 0.4932, -0.8489, -1.4104, -0.6753, 0.6808, 1.4109,0.8439, -0.4990])
如果我查看调试追踪目录中的 output_code.py 文件,会发现 torch 为我的 CPU 创建了一个优化后的 C++ 执行代码,这个代码将 foo 函数整合成了一个单一的执行单元。如果我在有 GPU 的情况下运行这个程序,torch 会为 GPU 创建一个 CUDA 执行代码。
#include "/tmp/torchinductor_user/ib/cibrnuq56cxamjj4krp4zpjvsirbmlolpbnmomodzyd46huzhdw7.h"extern "C" void kernel(const long* in_ptr0,float* out_ptr0){{#pragma GCC ivdepfor(long i0=static_cast<long>(0L); i0<static_cast<long>(10L); i0+=static_cast<long>(1L)){auto tmp0 = in_ptr0[static_cast<long>(i0)];auto tmp1 = static_cast<float>(tmp0);auto tmp2 = std::sin(tmp1);auto tmp3 = std::cos(tmp1);auto tmp4 = tmp2 + tmp3;out_ptr0[static_cast<long>(i0)] = tmp4;}}}
现在,处理过程简化为:
- 为最终结果张量分配与
x.shape()相同大小的内存 - 遍历
x(in_ptr0),计算每个元素的sin和cos值,并将它们相加得到结果
这种方法对于大型输入来说更加简单快速!
>>> x = torch.rand((10_000, 10_000))>>> %timeit foo(x)246 ms ± 8.89 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)>>> %timeit compiled_foo(x)91.3 ms ± 14 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)# (for small inputs `compiled_foo` was actually slower--not sure why)
需要注意的是,torch.compile 会根据我们传入的张量的具体大小(这里是 (10,))来优化代码。如果我们传入了多种不同大小的张量,torch.compile 会生成一个对大小不敏感的通用代码。但是,在某些情况下,固定大小的张量可以使编译器生成更优化的代码,例如通过循环展开或更有效的向量化操作。
在这个例子中,torch.compile 的使用展示了一些意料之外的效果:
def gbreak(x):r = torch.sin(x) + torch.cos(x)if r.sum() < 0:return r + torch.tan(x)else:return r - torch.tan(x)
该函数涉及基于运行时数据值的控制流决策,即根据变量的实时值执行不同的操作。如果我们采用和编译 foo 相同的方式来编译它,我们将得到两个不同的图(以及两个调试目录):
>>> compiled_gbreak = torch.compile(gbreak, options={"trace.enabled": True, "trace.graph_diagram": True})>>> compiled_gbreak(torch.tensor(range(10)))Writing FX graph to file: .../model__27_inference_63.9/graph_diagram.svg[2023-11-25 17:59:32,823] [9/0] torch._inductor.debug: [WARNING] model__27_inference_63 debug trace: /tmp/torchinductor_user/p3/cp3the7mcowef7zjn7p5rugyrjdm6bhi36hf5fl4nqhqpfdqaczp.debugWriting FX graph to file: .../graph_diagram.svg[2023-11-25 17:59:34,815] [10/0] torch._inductor.debug: [WARNING] model__28_inference_64 debug trace: /tmp/torchinductor_user/nk/cnkikooz2z5sms2emkvwj5sml5ik67aqigynt7mp72k3muuvodlu.debugtensor([ 1.0000, -0.1756, 2.6782, -0.7063, -2.5683, 2.7053, 0.9718, 0.5394,7.6436, -0.0467])
第一个内核负责执行函数中的 torch.sin(x) + torch.cos(x) 和 r.sum() < 0:
#include "/tmp/torchinductor_user/ib/cibrnuq56cxamjj4krp4zpjvsirbmlolpbnmomodzyd46huzhdw7.h"extern "C" void kernel(const long* in_ptr0,float* out_ptr0,float* out_ptr1,bool* out_ptr2){{{float tmp_acc0 = 0;for(long i0=static_cast<long>(0L); i0<static_cast<long>(10L); i0+=static_cast<long>(1L)){auto tmp0 = in_ptr0[static_cast<long>(i0)];auto tmp1 = static_cast<float>(tmp0);auto tmp2 = std::sin(tmp1);auto tmp3 = std::cos(tmp1);auto tmp4 = tmp2 + tmp3;out_ptr0[static_cast<long>(i0)] = tmp4;tmp_acc0 = tmp_acc0 + tmp4;}out_ptr1[static_cast<long>(0L)] = tmp_acc0;}}{auto tmp0 = out_ptr1[static_cast<long>(0L)];auto tmp1 = static_cast<float>(0.0);auto tmp2 = tmp0 < tmp1;out_ptr2[static_cast<long>(0L)] = tmp2;}}
而第二个内核处理 return r - torch.tan(x) 这一分支,因为这是在示例输入中执行的路径:
#include "/tmp/torchinductor_user/ib/cibrnuq56cxamjj4krp4zpjvsirbmlolpbnmomodzyd46huzhdw7.h"extern "C" void kernel(const float* in_ptr0,const long* in_ptr1,float* out_ptr0){{#pragma GCC ivdepfor(long i0=static_cast<long>(0L); i0<static_cast<long>(10L); i0+=static_cast<long>(1L)){auto tmp0 = in_ptr0[static_cast<long>(i0)];auto tmp1 = in_ptr1[static_cast<long>(i0)];auto tmp2 = static_cast<float>(tmp1);auto tmp3 = std::cos(tmp2);auto tmp4 = tmp0 - tmp3;out_ptr0[static_cast<long>(i0)] = tmp4;}}}
这种情况被称为图的分裂,这通常是不利的。这种分裂会导致编译后的函数运行速度下降,因为我们需要从优化的内核中退出,回到 Python 环境中去处理分支。此外,另一个分支(return r + torch.tan(x))还未编译,因为它尚未被执行。这意味着在需要时,它将进行即时编译,这在某些情况下(例如在处理用户请求时)可能导致不利影响。
torch._dynamo.explain 是一个很有用的工具,用于理解图分裂的情况:
# get an explanation for a given input>>> explained = torch._dynamo.explain(gbreak)(torch.tensor(range(10)))# there's a break, because of a jump (if) on line 3>>> explained.break_reasons[GraphCompileReason(reason='generic_jump TensorVariable()', user_stack=[<FrameSummary file <stdin>, line 3 in gbreak>], graph_break=True)]# there are two graphs, since there's a break>>> explained.graphs[GraphModule(), GraphModule()]# let's see what each graph implements, without needing to dive into the kernels!>>> for g in explained.graphs:... g.graph.print_tabular()... print()...opcode name target args kwargs------------- ------ ------------------------------------------------------ ------------ --------placeholder l_x_ L_x_ () {}call_function sin <built-in method sin of type object at 0x7fd57167aaa0> (l_x_,) {}call_function cos <built-in method cos of type object at 0x7fd57167aaa0> (l_x_,) {}call_function add <built-in function add> (sin, cos) {}call_method sum_1 sum (add,) {}call_function lt <built-in function lt> (sum_1, 0) {}output output output ((add, lt),) {}opcode name target args kwargs------------- ------ ------------------------------------------------------ ----------- --------placeholder l_x_ L_x_ () {}placeholder l_r_ L_r_ () {}call_function tan <built-in method tan of type object at 0x7fd57167aaa0> (l_x_,) {}call_function sub <built-in function sub> (l_r_, tan) {}output output output ((sub,),) {}# pretty cool!
torch.compile 等工具是优化代码、更有效地利用硬件性能的好方法,这样就无需使用 CUDA 这种传统方式来编写内核了。
(如果你想了解如何用传统方式编写内核,或者对这个过程感兴趣,我推荐阅读 这篇文章,它详细介绍了在 A6000 上尝试匹配 cuBLAS SGEMM 性能的经历。)
(并且,如果你对编译器的工作原理感兴趣,@tekknolagi 在 这篇文章 中探讨了如何将使用 micrograd 编写的模型编译到 C 语言,以实现 1000-7500 倍的速度提升!)
批量生成的优化
在 generate 函数的未优化版本中,我们每次只传递一个序列给模型,并请求它在每一步添加一个 Token:
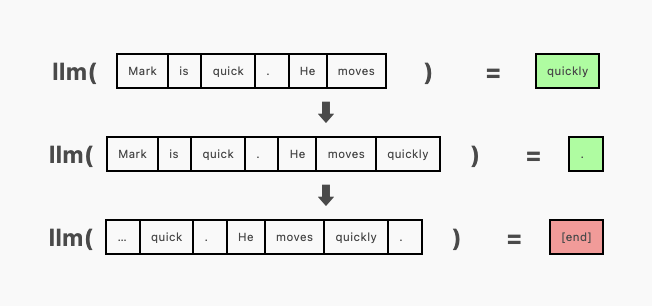
为了实现批量生成,我们一次性传递多个序列给模型,在同一轮计算中为每个序列生成输出。3 这就需要用填充 Token(我这里用 [end])将序列补齐到相同长度,且在注意力掩码中将这些填充 Token 屏蔽,避免它们影响生成过程。

由于这种方法可以让模型权重同时处理多个序列,因此整批序列的处理时间远少于分别处理每个序列的时间。例如,在我的计算机上,使用 GPT-2 生成下一个 Token 的时间大约是:
- 20 个 Token x 1 个序列 = 约 70 毫秒
- 20 个 Token x 5 个序列 = 约 220 毫秒(若线性增长则为约 350 毫秒)
- 20 个 Token x 10 个序列 = 约 400 毫秒(若线性增长则为约 700 毫秒)
持续批处理的优化
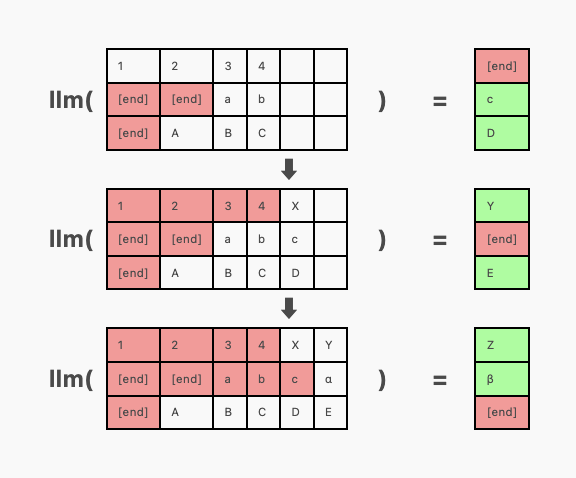
注意,在上面的例子中,“Mark is quick. He moves quickly.”这个序列比其他序列更早完成。但由于整个批次还未完成,我们不得不继续为它生成“Random”这样的 Token。这对生成结果的正确性没有影响——我们可以在 [end] Token 处截断生成的序列。但这样做意味着浪费了 GPU 资源,因为生成的部分 Token 我们最终会丢弃。
持续批处理通过在序列完成后的 [end] Token 之后,向批次中插入新的序列来解决这一问题。这样,我们不再在 [end] Token 后生成无关的 Token,而是在批次的相应位置插入新的序列。新序列通过注意力掩码实现,以防止它受到该位置之前序列 Token 的影响。(实际上,之前的序列就像是额外的填充物。)
缩减模型的权重
浮点数的大小对计算性能有显著影响。在大部分常规软件中(比如 Javascript 数字和 Python 的浮点数),我们通常使用 64 位的双精度 IEEE 754 浮点数。但在机器学习领域,传统上更倾向于使用 32 位的单精度 IEEE 754 浮点数:
>>> gpt2.transformer.h[0].attn.c_attn.weight.dtypetorch.float32
模型在使用 32 位浮点数(fp32)进行训练和推断时表现良好,而且这样可以为每个参数节省 4 字节,减少了一半的空间。以一个拥有 70 亿参数的模型为例,如果使用 64 位浮点数(fp64),它将占用 56 GB 的空间,而使用 fp32 只需要 28 GB。考虑到在训练和推断过程中有大量时间花在将数据从 RAM 移至缓存和寄存器,因此数据量越小,性能越好。所以尽管 fp32 比 fp64 更高效,但我们还可以进一步提升效率。
16 位浮点数
16 位浮点数(fp16),也就是半精度浮点数,是降低数据量的明显选择——再节省 50% 的空间!这里有两个主要选项:fp16 和 bfloat16(由 Google Brain 开发,因此得名“脑浮点数”),bfloat16 虽然范围更广,但硬件支持不足。
通过下面这张图表,我们可以清楚地看到每种类型中不同字段的大小:

在减少 fp32 字段时,fp16 和 bfloat16 做出了不同的选择:fp16 通过缩小指数和小数部分来平衡数值范围和精度,而 bfloat16 则保留了 8 位指数以维持与 fp32 相同的数值范围,但通过将小数部分缩小到比 fp16 更小的程度来牺牲精度。在 fp16 中,数值范围的缩减有时可能会影响训练的效果,但在进行推断时,不管是 fp16 还是 bfloat16 都能够胜任,如果你的 GPU 不支持 bfloat16,那么选择 fp16 可能更合适。
更小的模型?
我们是否可以制作更小尺寸的模型?当然可以!
一种做法是对原本使用较大数据格式(如 fp16)训练的模型进行“量化处理”。llama.cpp 项目及其相关的机器学习库 ggml,定义了多种量化处理方式(注意,README 目前可能不是最新的,请参考k-quants PR获取最新信息),这些方法可以把模型中每个数据单元的大小从 fp32 或 fp16 减少到不足 5 位。
量化处理的原理与 fp16 或 bfloat16 略有不同:在有限的空间内,无法容纳完整的数字。因此,我们采用“分块量化”的方法:以 fp16 作为每个数据块的比例基准,然后将每个数据块的量化值与这个比例基准相乘。在某些格式中,还会设定一个最小值,有时甚至将比例基准和最小值进一步量化,以使其体积更小(比 fp16 小)。这个过程非常复杂,想要深入了解可以查阅 k-quants PR 和这篇博文。
另外,bitsandbytes 这个项目也为非 llama.cpp 的项目提供了量化功能。(不过我个人对此不太熟悉,只是在 Lambda Labs 的系统中作为一个附加组件遇到过一些安装问题 :-))
但是,如果在量化处理中使用的参数比原模型的参数范围小很多,那么可能会影响模型的性能,降低回应的质量。因此,选择最低限度的量化处理,以获得可接受的运算速度是最佳选择。
此外,我们也可以使用比 fp16 更小的数据类型来进行模型训练或微调。例如,可以通过qLoRA训练量化的低秩适配器,而且根据2022 年的一篇研究论文,使用(模拟的)fp8 数据格式训练的 175B 参数语言模型,其效果与使用 fp16 相近。
需要注意的是,到 2023 年为止,GPU 通常不支持小于 fp16(16 位浮点数)的数据类型,唯一的例外是 int8(8 位整数)。尽管可以使用 int8 进行一定程度的训练和推理,但大多数情况下的量化需要在计算时将权重从量化格式转换为其他类型(比如 fp16),计算完成后再转换回原格式,这个过程会产生一定的性能损耗。这种损耗是否值得,取决于您的 GPU 的内存大小以及内存速度,但需要明白的是,进行量化并非没有成本。
KV 缓存机制
为了解释 KV 缓存机制,我要引用我之前的文章中的一些图解,那篇文章详细介绍了 Transformer 的工作原理。如果您对 KV 缓存的概念感到陌生,请先阅读那篇文章以获得更全面的了解!这里的解释主要基于 GPT-2 模型,因为那是我在上一篇文章中分析的。尽管其他的架构在某些方面有所不同,但对于理解 KV 缓存的基本原理影响不大。
在 Transformer 的内部,激活信号会通过前馈层,转换成一个名为 qkv 的矩阵,其中每一行都与一个 Token(词元)相对应:

Then, the qkv matrix is split into q, k, and v, which are combined with attention like this:
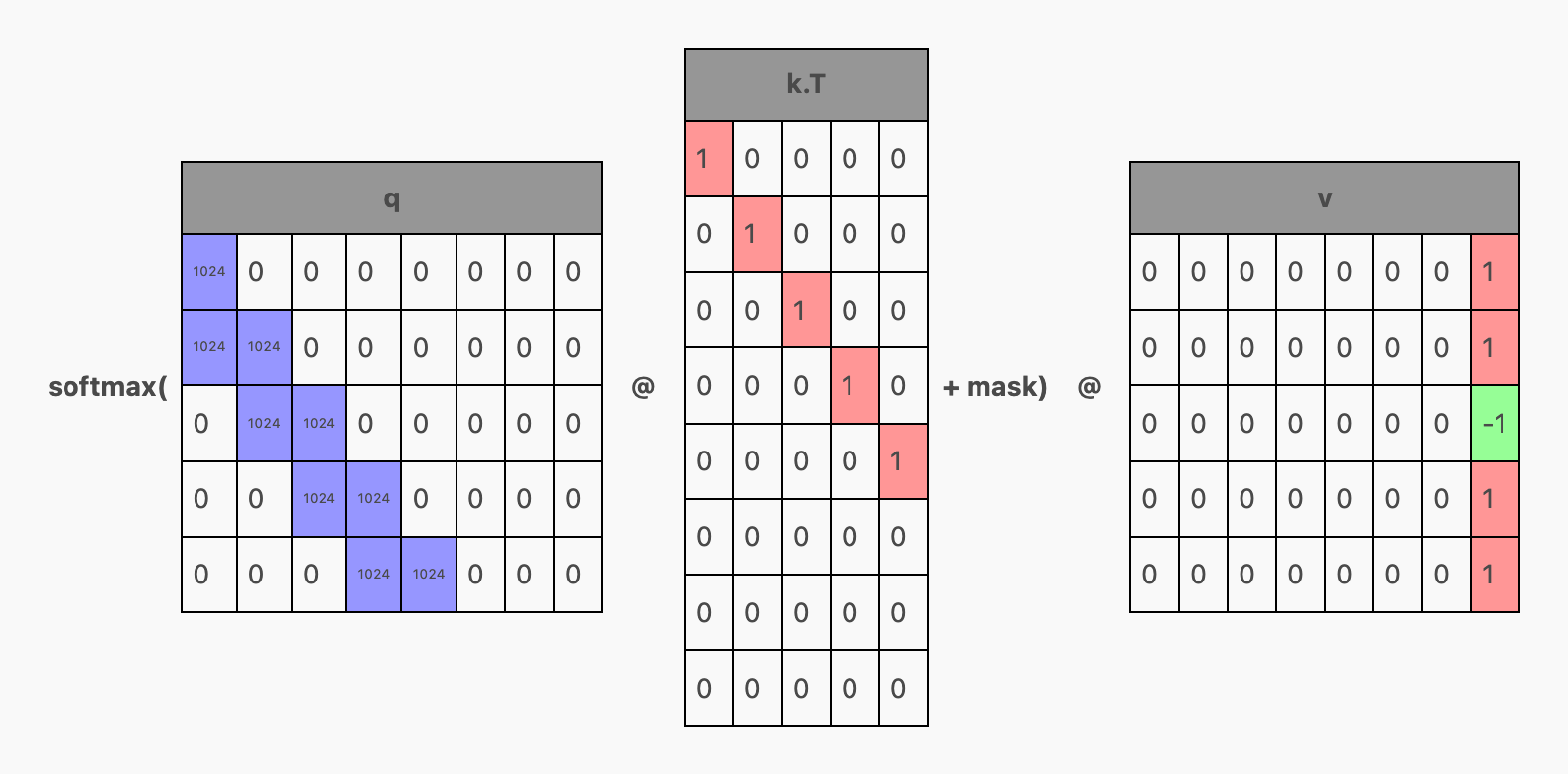
To produce a matrix like this:
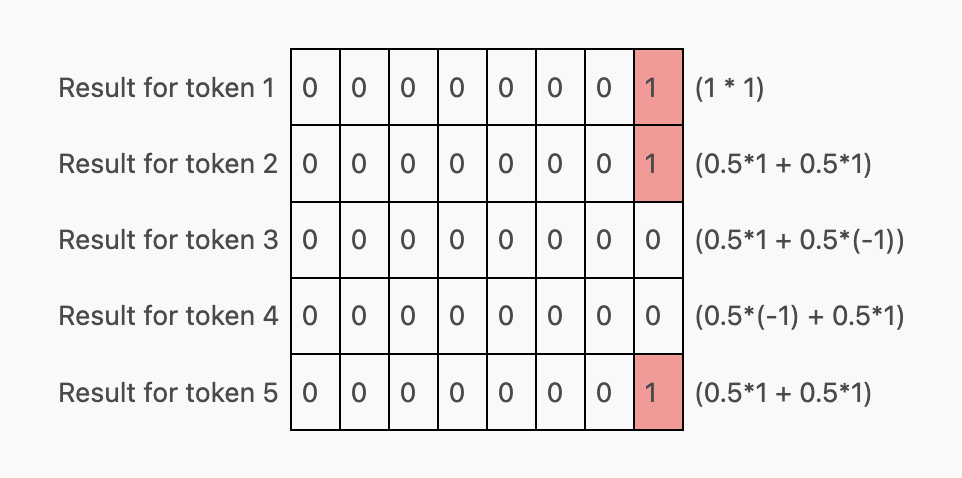
根据这些行在 Transformer 结构中的位置,它们可能在经过 MLP(多层感知机)处理后,作为下一个 Transformer 单元的输入,或者用于预测下一个 Token。需要注意的是,Transformer 被设计为能够针对上下文窗口中的 每一个 Token 预测下一个 Token。
# the gpt2 tokenizer produces 3 tokens for this string>>> tokens = tokenizer(" A B C").input_ids>>> tokens[317, 347, 327]# if we put that into the model, we get 3 rows of logits>>> logits = gpt2(input_ids=torch.tensor(tokens)).logits.squeeze()>>> logits.shapetorch.Size([3, 50257])# and if we argmax those, we see the model is predicting a next token# for _every_ prompt token!>>> for i, y in enumerate(logits.argmax(-1)):... print(f"{tokenizer.decode(tokens[:i+1])!r} -> {tokenizer.decode(y)!r}")' A' -> '.'' A B' -> ' C'' A B C' -> ' D'
在训练过程中,这种方式非常有效,因为它允许多个 Token 参与计算,而不仅仅是一个,这样一来,信息流向 Transformer 的量就更大了。但在实际应用(推理)中,我们通常只关注最后一行——也就是对最后一个 Token 的预测结果。
那么,我们如何从一个被训练来预测整个上下文的 Transformer 中仅提取出这部分信息呢?让我们回到注意力计算的过程。如果 q 只代表最后一个 Token 的那一行数据会怎样?
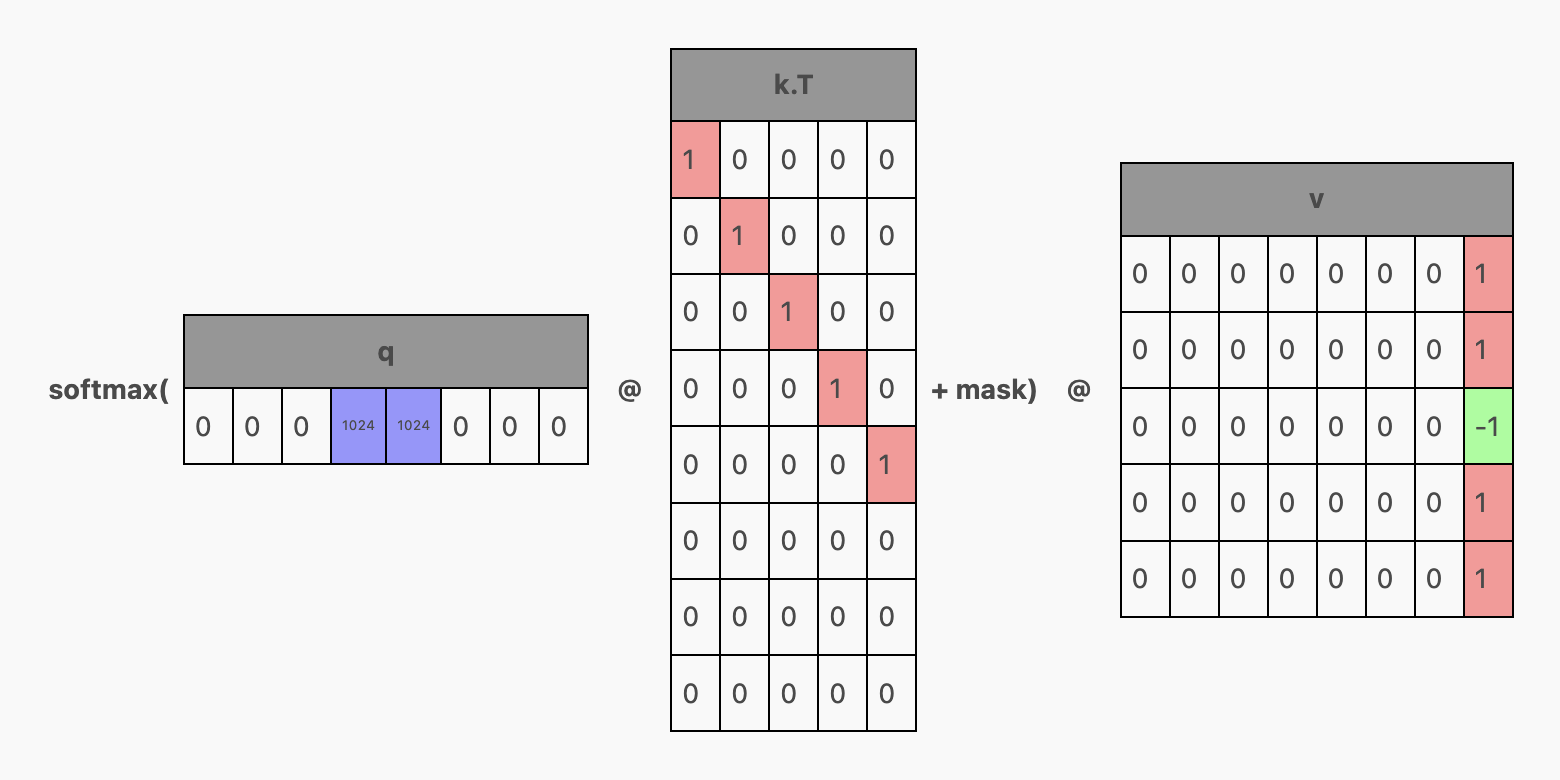
Then, we'd get this as the attention result—just the result for the last token, exactly like what we want.

这听起来很不错,但要想仅生成 q 的最后一行,我们还必须限制生成 qkv 矩阵的层只对单行数据进行处理。那么,剩余的 k 和 v 行数据从何而来呢?答案就藏在 KV 缓存的名字里——我们重用之前生成 Token 步骤中计算得到的 KV 值。模型内部会保存每个 Transformer 单元在注意力计算期间产生的 KV 数据。在下一轮生成时,只有一个新的 Token 被输入,而之前缓存的 KV 行将与这个新 Token 对应的 K 和 V 行叠加,形成我们所需的单行 Q 和多行 K、V。
下面是一个利用 HuggingFace 的 transformers API 进行 KV 缓存的示例。这个 API 默认会在模型前向传递时返回 KV 缓存。这个缓存是一个元组,包括每层的 (k, v) 对。这里的 k 和 v 张量的形状分别为 (batch_size, n_head, n_seq, head_size)。
>>> tokens[317, 347, 327] # the " A B C" string from before>>> key_values = gpt2(input_ids=torch.tensor(tokens)).past_key_values>>> tuple(tuple(x.shape for x in t) for t in key_values)((torch.Size([1, 12, 3, 64]), torch.Size([1, 12, 3, 64])),(torch.Size([1, 12, 3, 64]), torch.Size([1, 12, 3, 64])),(torch.Size([1, 12, 3, 64]), torch.Size([1, 12, 3, 64])),(torch.Size([1, 12, 3, 64]), torch.Size([1, 12, 3, 64])),(torch.Size([1, 12, 3, 64]), torch.Size([1, 12, 3, 64])),(torch.Size([1, 12, 3, 64]), torch.Size([1, 12, 3, 64])),(torch.Size([1, 12, 3, 64]), torch.Size([1, 12, 3, 64])),(torch.Size([1, 12, 3, 64]), torch.Size([1, 12, 3, 64])),(torch.Size([1, 12, 3, 64]), torch.Size([1, 12, 3, 64])),(torch.Size([1, 12, 3, 64]), torch.Size([1, 12, 3, 64])),(torch.Size([1, 12, 3, 64]), torch.Size([1, 12, 3, 64])),(torch.Size([1, 12, 3, 64]), torch.Size([1, 12, 3, 64])))
如果我们把这个返回的 KV 缓存再次用于模型前向传递,模型会认为我们之前用来生成这个缓存的 tokens 仍然存在,尽管我们并没有再次输入它们。值得注意的是,我们在这里只传递了一个 token,因此也只获得了一行 logits 的结果。
>>> new_token = tokenizer(" D").input_ids>>> new_token[360]>>> logits = gpt2(input_ids=torch.tensor(new_token), past_key_values=key_values).logits>>> logits.shapetorch.Size([1, 50257])>>> tokenizer.decode(logits.argmax(-1))' E'
将这个情况与我们只输入一个 token 而不是 输入 past_key_values 进行比较——虽然我们得到了一个完成的结果,但它并没有考虑到生成 KV 缓存时的那些先前 tokens。
>>> tokenizer.decode(gpt2(input_ids=torch.tensor(new_token)).logits.argmax(-1))'.'
(另外,比如 lit-gpt 就提供了一个更友好的 KV 缓存 API,它可以自动处理缓存,而不是需要我们手动传递 :-) )
KV 缓存技术在减缓大语言模型 (LLM) 在算法上的运行缓慢方面发挥了作用。因为我们在每一步只输入一个 token,所以不需要为每一个新的 token 重复所有计算。然而,这并不意味着问题完全解决,因为 KV 缓存的体积会随着每一步的增长而扩大,导致注意力计算的速度变慢。KV 缓存的体积增长本身也可能成为一个新的问题。例如,对于一个包含 1,000 个 token 的 KV 缓存,即使是最小的 GPT-2 模型也需要缓存 18,432,000 个值。如果每个值都是一个 fp32 类型,那么仅仅是缓存就几乎要占用 74MB,这对于一个相对较小的模型在单次生成中的占用是相当大的!对于规模更大的现代模型来说,尤其是在需要同时处理多个客户端的服务器上,KV 缓存的管理可能很快就会变得困难,因此出现了一些技术来解决这个问题。
多重查询关注机制
多重查询关注机制是对模型结构的一种调整,它通过给查询部分 (Q) 分配多个处理单元,而将键 (K) 和值 (V) 部分只分配给一个处理单元,从而减小了键值 (KV) 缓存的大小。这种调整需要从模型训练的初期就开始实施,不仅仅是在推理时的优化。了解这一点对选择模型非常重要,因为采用了这种机制的模型能够在键值缓存中处理更多的 token,相比之下,使用传统关注机制训练的模型则不具备这种能力。要理解这个概念,我们首先需要了解一下多头关注机制,让我们先简单介绍一下。
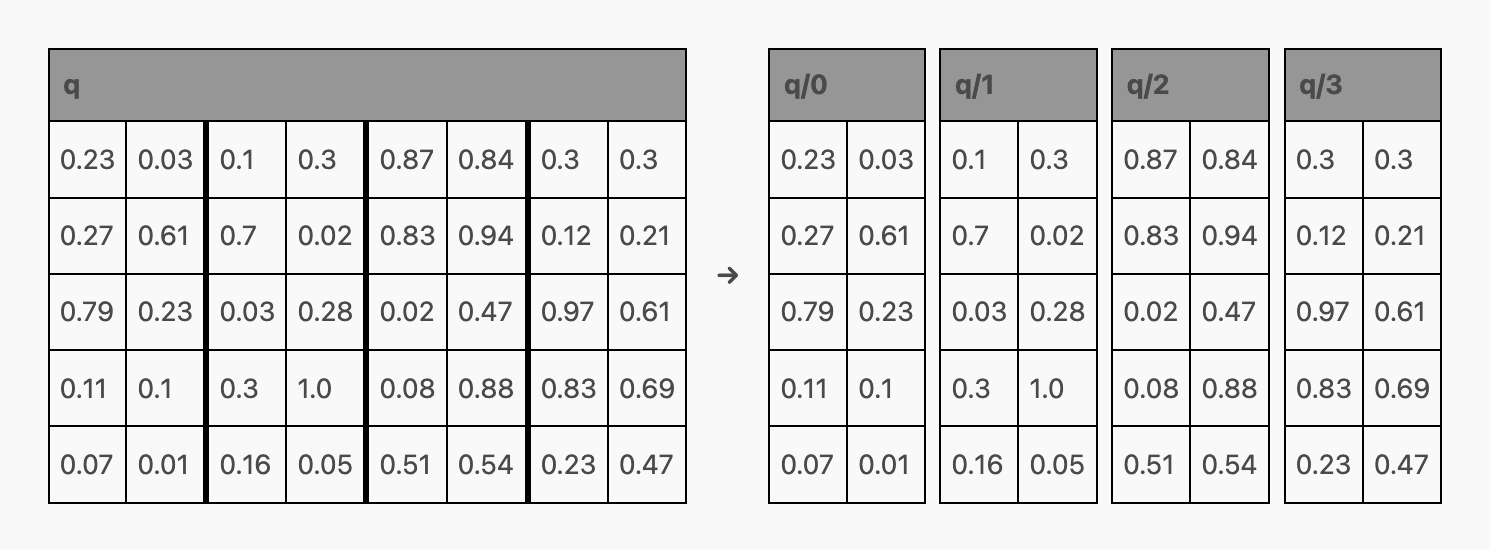
现代大语言模型 (LLM) 通常不会一次性对整个查询 - 键 - 值 (QKV) 矩阵进行处理,而是将其分割成多个较小的单元,我们称之为“头部”。这意味着与上文图示不同,实际情况更像是这样:


Then each head is combined in attention as before:

这些较小的结果矩阵会被重新组合,形成最终的结果矩阵,其结构为 (序列长度, 嵌入大小),与传统关注机制的结果相似。这种做法允许每个头部承担不同的任务(例如,一个头部专注于处理首字母缩写中的标点,另一个则处理法语文章),而不是将一个完整的 Transformer 模块只用于单一任务。
那么,什么是 多重查询关注机制 呢?与传统的多头关注机制不同,这里只有 查询部分 (Q) 被分割成多个头部。键 (K) 和值 (V) 的大小与单个头部相当,而且这唯一的键和值在所有查询头部之间共享。


你可能会认为这种设计会严重影响模型的性能,但实际上它对模型的困惑度(一种衡量模型预测能力的指标)影响很小。MQA 论文中的表格显示,尽管其结果略逊于多头关注机制的基线水平,但仍优于其他缩小了多头关注机制各维度的方案。
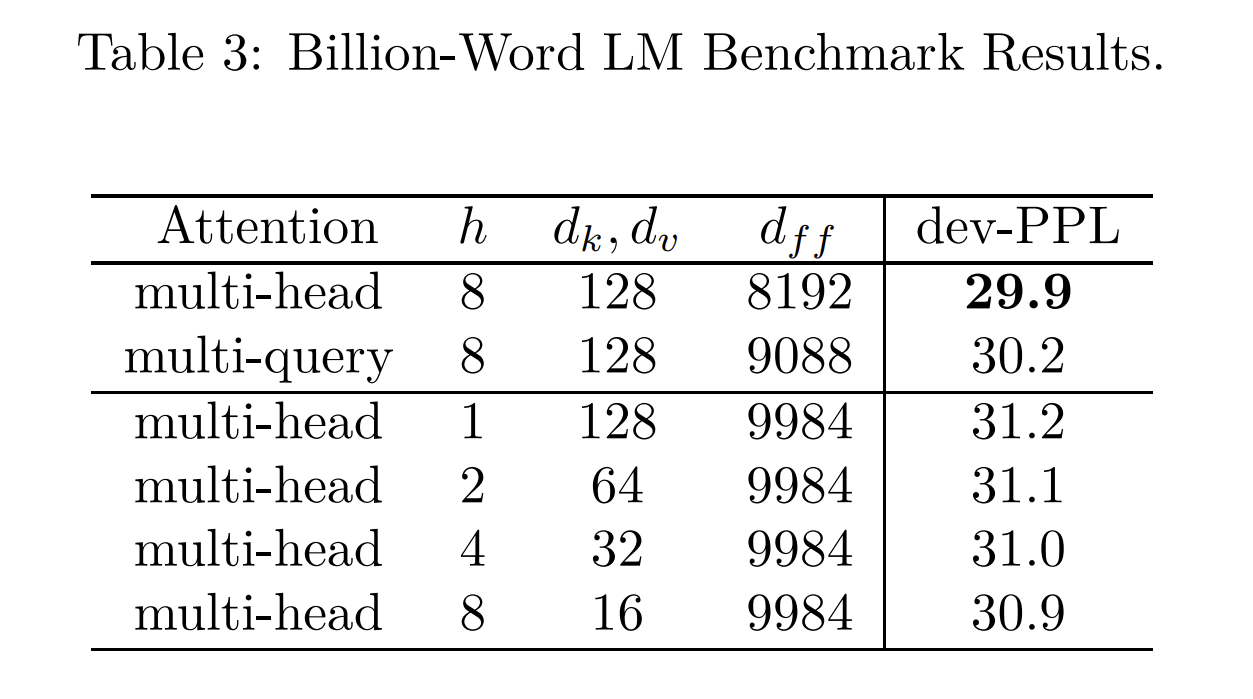
其优势在于,由于键 (K) 和值 (V) 的尺寸远小于传统多头关注机制中的尺寸,因此键值 (KV) 缓存也相应更小。例如,LLAMA-2 和 Falcon 这两种模型就因为这个原因采用了多重查询关注机制。
Mistral 7B 采用了一种名为分组查询注意力 (Grouped-Query Attention)的新变体,这是多头查询注意力 (MQA) 和多头自注意力 (MHA) 的混合版本。在这种方法中,如果多头自注意力 (MHA) 是 Q_heads=K_heads=V_heads=N,多头查询注意力 (MQA) 是 Q_heads=N; K_heads=V_heads=1,那么分组查询注意力 (GQA) 就定义为 Q_heads=N; K_heads=V_heads=G,其中 1 < G < N。GQA 有一个显著特点:与 MQA 相比,它对模型的困惑度(即模型对数据的预测能力)的影响更小,且训练更加稳定。
PagedAttention
使用大型键值 (KV) 缓存的一个问题是,这种缓存通常需要以连续的数据块(张量)形式存储,无论缓存是否全部被利用。这带来了几个问题:
- 我们需要预先分配比实际使用更多的空间,以预备 KV 缓存可能达到的最大容量。
- 这些预留的空间即使暂时用不到,也不能被其他请求利用。
- 如果请求有相同的前缀,它们也不能共享该前缀的 KV 缓存,因为后续它们的数据可能会有所不同。
PagedAttention 通过借鉴操作系统处理程序内存问题的方式,解决了这些挑战。
让我们简单了解一下操作系统的内存分页机制。程序希望它们的内存呈现为一整块连续的线性空间。举例来说,如果我分配了一个一百万字节的数组 x,我期望 x[n + 1] 的地址正好是 x[n] 后面的一个字节(许多程序代码都是基于这个假设的)。但在现实中,物理内存并非总能满足这种需求,操作系统不得不处理诸如“内存碎片化”和“你请求了一个 1TiB 的大内存块,我没法找到合适的位置”等问题。
因此,操作系统与硬件协作,利用内存管理单元 (MMU) 在页表中将虚拟页映射到物理页。当你在程序中访问一个地址时,这个地址会通过页表(以及 TLB 缓存)从程序的地址空间转换到物理地址,然后才进行读写操作。值得注意的是,这个物理地址可能是按需生成的,也就是说,在你写入数据之前它可能并不存在。比如,我们可以在 C 语言中映射 16 个内存页:
uint8_t *pages = mmap(NULL, page_size * 16,PROT_READ | PROT_WRITE,MAP_PRIVATE | MAP_ANONYMOUS,-1, 0);
如果我们对这个运行中的程序进行pagemap-dump,我们会得到一个包含页面地址和相应 pfn 物理地址的列表(以及其他元数据):
# addr pfn soft-dirty file/shared swapped present library7fbe0fe6a000 0 1 0 0 07fbe0fe6b000 0 1 0 0 07fbe0fe6c000 0 1 0 0 07fbe0fe6d000 0 1 0 0 07fbe0fe6e000 0 1 0 0 07fbe0fe6f000 0 1 0 0 07fbe0fe70000 0 1 0 0 07fbe0fe71000 0 1 0 0 07fbe0fe72000 0 1 0 0 07fbe0fe73000 0 1 0 0 07fbe0fe74000 0 1 0 0 07fbe0fe75000 0 1 0 0 07fbe0fe76000 0 1 0 0 07fbe0fe77000 0 1 0 0 07fbe0fe78000 0 1 0 0 07fbe0fe79000 0 1 0 0 0
请注意,所有页面的物理地址都是零——它们实际上还不存在!这种情况被称为 内存过度分配 (memory overcommit)。内核不确定我们是否真的需要这些内存页面,因此它暂时不会为它们创建内存映射。如果试图从这些未初始化的内存中读取数据,可能会得到一个不确定的值(这也是为什么在 C 语言中读取未初始化内存可能导致未定义行为 (UB))。
然而,如果我开始逐一写入这些页面...
// pages is our page_size * 16 map from earlierfor (int i = 0; i < page_size * 16; i++) pages[i] = 1;
...内存的状态就会发生变化!
# addr pfn soft-dirty file/shared swapped present library7fbe0fe6a000 14a009 1 0 0 17fbe0fe6b000 50eca5 1 0 0 17fbe0fe6c000 175a5d 1 0 0 17fbe0fe6d000 148d85 1 0 0 17fbe0fe6e000 2de86c 1 0 0 17fbe0fe6f000 13a300 1 0 0 17fbe0fe70000 8f25b4 1 0 0 17fbe0fe71000 15ae63 1 0 0 17fbe0fe72000 6e1d7f 1 0 0 17fbe0fe73000 13a307 1 0 0 17fbe0fe74000 14a074 1 0 0 17fbe0fe75000 14a0a7 1 0 0 17fbe0fe76000 7e2662 1 0 0 17fbe0fe77000 1ccdc2 1 0 0 17fbe0fe78000 2a4f06 1 0 0 17fbe0fe79000 2169ef 1 0 0 1
这时,每个页面都被分配了一个实际的物理地址,因为它们已经被写入数据。但请注意,这些物理地址并不像虚拟地址那样按顺序排列。它们被分散存放在内存的各个角落。例如,如果我们的 C 程序只修改了一半的页面,那么只有这部分页面会被实际映射到物理内存,其余的仍然不会被使用。这意味着物理内存只有在真正需要的时候才会被分配。
我还可以选择只和另一个进程共享部分内存。比如,我映射了四个页面作为共享内存:
7fbe0fe6a000 14a0097fbe0fe6b000 50eca57fbe0fe6c000 175a5d7fbe0fe6d000 148d85
另一个进程看到的页面可能是这样的:
5581627bb000 14a0095581627bc000 50eca55581627bd000 175a5d5581627be000 148d85
尽管它们的虚拟地址不同,但物理地址是完全相同的!这意味着,尽管两个程序在不同的上下文中看到这些页面,但它们实际上是存储在物理内存的同一位置。
那么,这个概念如何应用于 PagedAttention 呢?PagedAttention 的原理和这个是一样的——正如论文中所描述的那样。4
在 PagedAttention 中,我们处理的不是内存页面,而是用于存储 Token 的 KV 缓存块。而且,不是进程,而是大语言模型(LLM)的请求来访问这些 Token 块。
启动时,PagedAttention 会为每个请求创建一个 块表,这个表在开始时是空的,没有任何块被映射,就像我们前面提到的 C 程序一样。
在这种方法中,我们不再是将每个请求与一个庞大的键值 (KV) 缓存项关联起来,而是为每个请求分配一个相对较小的块索引列表,这有点像操作系统分页技术中的虚拟地址。这些索引指向存储在一个全局块表中的数据块。与操作系统中的页面类似,这些块可以是乱序的,可以放置在任何有空间的地方:
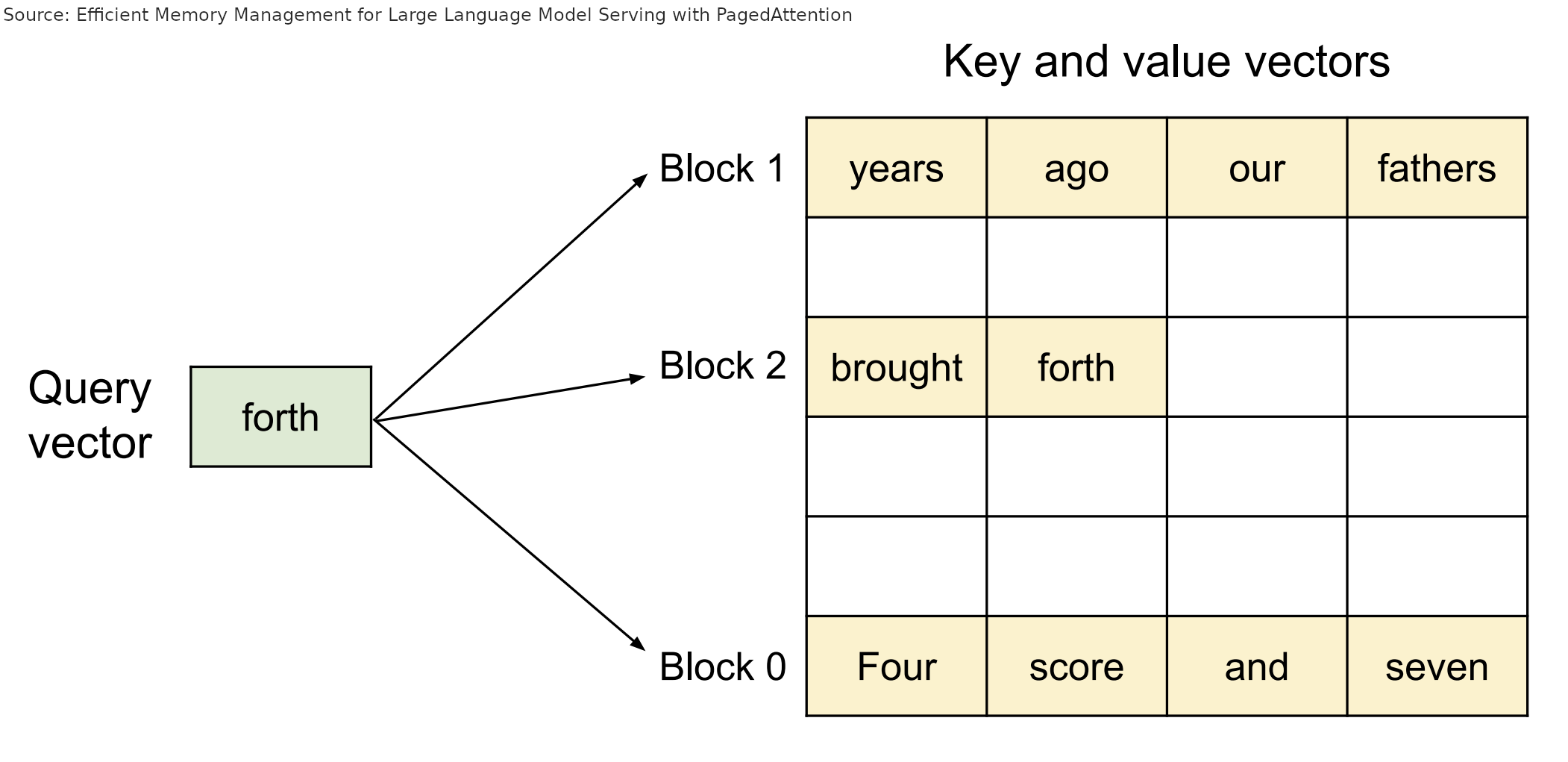
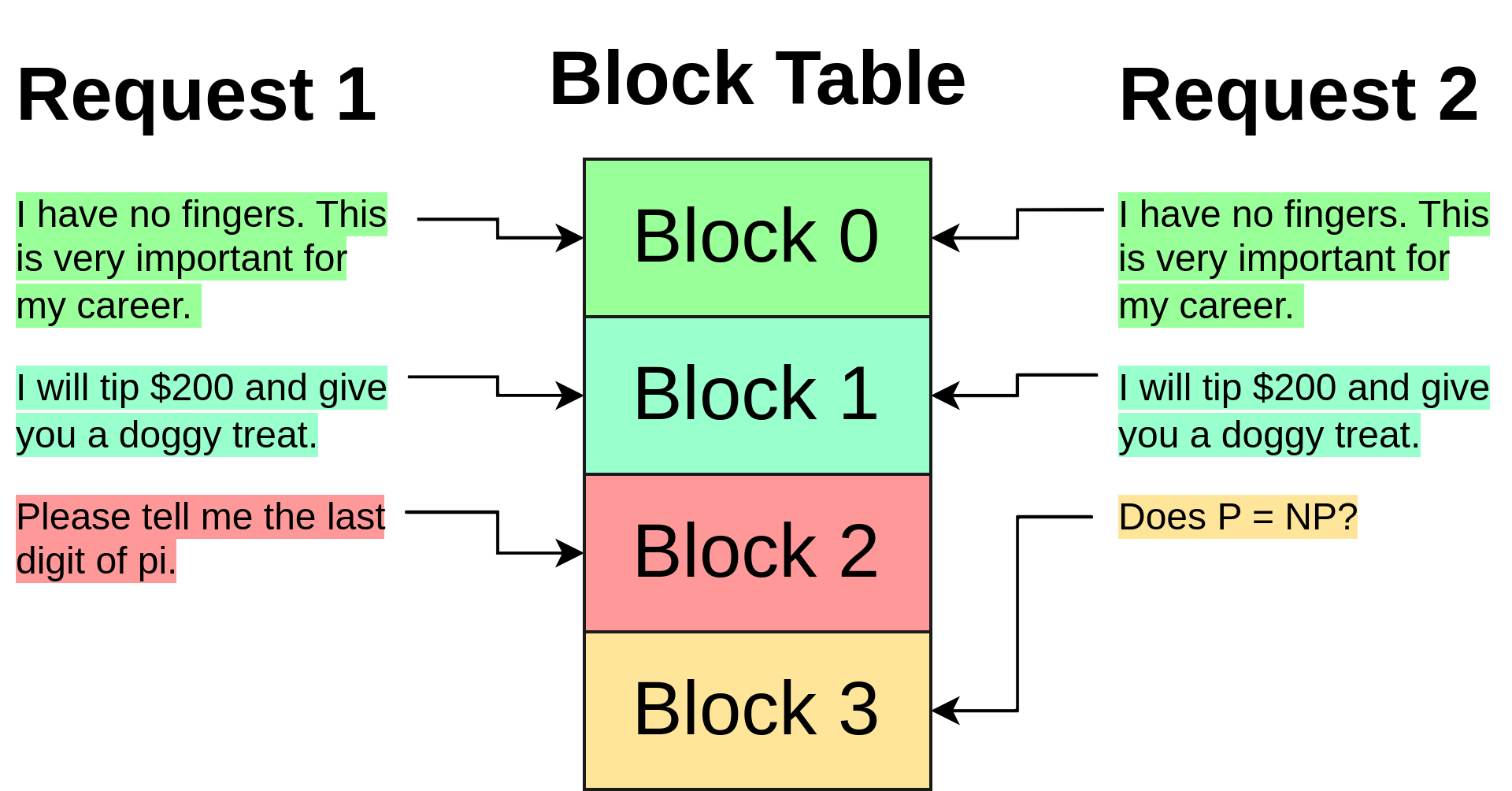
在执行注意力计算时,PagedAttention 机制会遍历请求中的块索引列表,从全局块表中取出相应的块,并以正确的顺序进行正常的注意力计算。
重要的是,由于这些数据块已经不再与特定的请求直接绑定,它们可以像操作系统分页中的共享内存那样被多个请求共享。比如,如果两个请求使用了相同的长前缀(如多个并行翻译任务中的几个 k-shot 实例,最近的 Twitter 提示技巧,或者是用于增强一致性思考的连贯思维链条等),那么这个前缀的键值 (KV) 缓存块就可以被多个请求共用,只需将该数据块的索引放在每个请求的索引列表中相应的位置即可。
投机性解码
想要理解投机性解码,你需要记住三个关键点。
首先,由于内存访问的开销,让模型处理少量 Token 的时间几乎与处理单个 Token 相同:
其次,大语言模型 (LLM) 会对上下文中的每一个 Token 进行预测:
>>> for i, y in enumerate(logits.argmax(-1)):... print(f"{tokenizer.decode(tokens[:i+1])!r} -> {tokenizer.decode(y)!r}")' A' -> '.'' A B' -> ' C'' A B C' -> ' D'
最后,有些词语是很容易预测的。比如,在 "going" 这个词之后,你不用是 GPT-4 也能猜到 "to" 很可能是下一个词。
我们可以利用这些原理来优化文本生成!想象一下,如果最新的 Token 是 "going",那我们在启动生成过程前就可以乐观地加上 "to"。之后,在模型运行结束后,我们检查模型是否也预测 "going" 后面跟着 "to"。如果是的话,我们就像是免费获得了一个 Token("to")。如果不是,也没关系,我们只接受模型为 "going" 所预测的 Token,因为这正是模型在没有我们这个小技巧时会生成的 Token。
def generate(prompt: str, tokens_to_generate: int) -> str:tokens: list[int] = tokenize(prompt)GOING, TO = tokenize(" going to")for i in range(tokens_to_generate):if tokens[-1] == GOING:# do our speculative decoding tricklogits = model.forward(tokens + [TO])# the token the model predicts will follow "... going"going_pred = argmax(logits[-2, :])# the token the model predicts will follow "... going to"to_pred = argmax(logits[-1, :])if going_pred == TO:# if our guess was correct, accept "to" and the next token aftertokens += [TO, to_pred]else:# otherwise, accept the real next token# (e.g. "for" if the true generation was "going for broke")tokens += [going_pred]else:# do normal single-token generationlogits = model.forward(tokens)tokens += [argmax(logits[-1])]return detokenize(tokens)
这种方法绝对可行,并能为你带来一点速度提升。要进一步优化这个方法,你可以考虑加入更多的启发式规则:例如,在逗号后面预测 "and",在 "is" 后面预测 "the"。你甚至可以考虑多词的启发式规则:比如看到 "The early bird",何不乐观地加上 "catches the worm" 呢?即使他们对这个短语有所改动,你至少还能准确预测到 "catches" 和 "the",不必完全接受整个短语。
但是,为什么要手动制定这些规则呢?我们正在尝试找到 Token 可能的续接部分……而这正是语言模型的强项!如果我们利用语言模型来生成我们乐观的 Token,我们就能够捕捉到更复杂的模式,甚至是之前上下文中的模式。
我们只需使用一个小型且运行迅速的“草稿”模型,它通过减少对较大“神谕”模型的多次使用,来自行弥补运行成本。一个有效的经验法则是,这个模型的规模约为神谕模型的 1/10。此外,它还应采用与神谕模型相同的 tokenizer(Token 处理器),以避免重复对序列进行 detokenize(解码)和 retokenize(重新编码)。
下面是引入草稿模型的生成循环示例:
def generate(prompt: str, tokens_to_generate: int, n_draft: int = 8) -> str:tokens: list[int] = tokenize(prompt)for i in range(tokens_to_generate):# generate `n_draft` draft tokens in the usual autoregressive waydraft = tokens[:]for _ in range(n_draft):logits = draft_model.forward(draft)draft.append(argmax(logits[-1]))# run the draft tokens through the oracle model all at oncelogits = model.forward(draft)checked = logits[len(tokens) - 1 :].argmax(-1)# find the index of the first draft/oracle mismatch—we'll accept every# token before it# (the index might be past the end of the draft, if every draft token# was correct)n_accepted = next(idx + 1for idx, (checked, draft) in enumerate(# we add None here because the oracle model generates one extra# token (the prediction for the last draft token)zip(checked, draft[len(tokens) :] + [None]))if checked != draft)tokens.extend(checked[:n_accepted])return detokenize(tokens)
在这个例子中,我以 GPT-2-XL(1558M 参数)作为神谕模型,GPT-2-small(124M 参数)作为草稿模型,并设置 n_draft=8。绿色 token 是草稿模型生成的,而蓝色 token 表示草稿模型错误,必须采用神谕模型的正确 token。

可以看到,草稿模型特别擅长快速复制问题文本(如“张量是”),顺畅衔接常见的词组(如“它” -> “是一个”),并添加常用短语(如“一组数据点”),这样神谕模型只需在关键词上进行调整。
另一个例子,设置相同但用不同的提示词:

在这里,草稿模型在处理字母表部分时表现出色,甚至多次达到了生成限制(例如,“L”本可以被正确预测,但我们限制了一次最多生成 8 个 token)。然而,一旦开始生成下方的文本,草稿模型就开始跟不上节奏了。
最后,这是一个极端案例:

最初,两个模型保持一致,但不久后就开始出现分歧。由于草稿模型的准确性下降,文本生成变得异常缓慢。每生成一个 token,就有 8 个草稿 token 被产生然后立刻废弃。
这展示了推测性解码的性能极度依赖于具体上下文!如果初步模型与预测准确的参考模型(oracle model)高度一致,并且文本容易预测,你就能快速生成大量初步 Token,从而实现迅速的计算过程。但若两个模型之间没有关联,推测性解码反而可能拖慢整个计算过程,因为你在生成最终可能会被舍弃的初步 Token 上浪费了时间。
阈值解码介绍
为了解决使用固定数量草稿 Token 带来的问题,我提出了一个新方法:阈值解码。
这种方法不是简单地按最大草稿 Token 数量进行解码,而是设定一个随时变动的概率阈值。这个阈值会根据目前接受的 Token 数来调整。只要草稿的累积概率(基于模型的预测概率)高于这个阈值,就会继续生成 Token。
举个例子,假设阈值设为 0.5,当我们生成了一个概率为 0.75 的草稿 Token " the",我们就会继续生成。但如果接下来的 Token " next" 概率只有 0.5,使得累积概率降至 0.375,低于阈值,我们就会停止,并把这两个 Token 提交给判定系统。
随后,根据草稿接受的进度,系统会调整阈值的高低,以此来平衡模型的预测信心和实际的接受率。目前,这一调整主要依靠移动平均和一些基本的阈值设定,但理论上可以采用更加科学的统计方法来实现。
下面是相关代码(使用我自制的框架,敬请谅解):
def speculative_threshold(prompt: str,max_draft: int = 16,threshold: float = 0.4,threshold_all_correct_boost: float = 0.1,):tokens = encoder.encode(prompt)# homegrown KV cache setup has an `n_tokens` method that returns the length# of the cached sequence, and a `truncate` method to truncate that sequence# to a specific tokenmodel_kv = gpt2.KVCache()draft_kv = gpt2.KVCache()while True:# generate up to `max_draft` draft tokens autoregressively, stopping# early if we fall below `threshold`draft = tokens[:]drafted_probs = []for _ in range(max_draft):logits = draft_model.forward(draft[draft_kv.n_tokens() :], draft_kv)next_id = np.argmax(logits[-1])next_prob = gpt2.softmax(logits[-1])[next_id]if not len(drafted_probs):drafted_probs.append(next_prob)else:drafted_probs.append(next_prob * drafted_probs[-1])draft.append(int(next_id))if drafted_probs[-1] < threshold:breakn_draft = len(draft) - len(tokens)# run draft tokens through the oracle modellogits = model.forward(draft[model_kv.n_tokens() :], model_kv)checked = logits[-n_draft - 1 :].argmax(-1)n_accepted = next(idx + 1for idx, (checked, draft) in enumerate(zip(checked, draft[len(tokens) :] + [None]))if checked != draft)yield from checked[:n_accepted]tokens.extend(checked[:n_accepted])if n_accepted <= n_draft:# adjust threshold towards prob of last accepted token, if we# ignored any draft tokensthreshold = (threshold + drafted_probs[n_accepted - 1]) / 2else:# otherwise, lower the threshold slightly, we're probably being# too conservativethreshold -= threshold_all_correct_boost# clamp to avoid pathological thresholdsthreshold = min(max(threshold, 0.05), 0.95)# don't include oracle token in kv cachemodel_kv.truncate(len(tokens) - 1)draft_kv.truncate(len(tokens) - 1)
下表展示了阈值解码和常规固定长度草稿解码的对比,这里还包括了 KV 缓存以保证比较的公正性。这是基于我之前展示的测试提示得出的结果。表格最右侧的列展示了生成速度随时间的变化趋势。

可以看到,比如在 "Index: A B C" 的测试中,当草稿长度设为 16 时,初始阶段表现不错,但在随后的散文部分由于过度生成不正确的 Token 而表现下滑。而阈值解码则能够在简单的字母部分加速生成,而在难度较高的散文部分适时减速,避免过度生成:

分阶段推测性解码
在分阶段推测性解码中,相较于传统的推测性解码,新增了两项重要的改进:
首先,它将文本草稿的生成过程重新构建成树状结构,而不是单线生成。这种方式对于处理复杂文本特别有效,因为长篇的文本草稿容易与原始模型产生偏差。采用多个短草稿,它们相互分支,然后利用特定设计的注意力掩码(attention mask),与预测模型(oracle model)进行核对。这种方法通过生成多个草稿序列,不仅可以重复使用先前的 Token(词元),而且还能批量采样草稿模型,极大地提高了处理速度。
(你可以把常规的推测性解码理解为“深度”探索,而树状结构的方法则是“广度”探索。这引发了一个问题:在处理特定文本时,应如何平衡“深度”与“广度”的优先级?也许像在“阈值解码”部分提到的可调整参数,在这里也同样适用。)
第二个改进是对草稿模型本身也应用推测性解码,毕竟它通常基于 Transformer 架构。这可能是一个规模更小的 Transformer(推荐规模为预测模型的 15-20 分之一),或者甚至是一个简单的 N-gram 模型。
引导式生成
语法引导生成技术可以约束模型的输出,使其符合特定的语法规则,从而确保输出内容符合某种语法标准——比如 JSON。乍一看,这似乎与提升运行速度无关——毕竟,提高可靠性是一回事,但提速似乎不太可能!然而,实际上这是可行的——让我们深入其工作机制,来理解背后的原因。
设想你正在使用大语言模型 (LLM) 来生成 JSON,而目前生成的内容如下:
{"key":
GPT-4 在这一环节可以生成超过 10 万个 Token,但实际上只有极少数是合法的,比如空格、开括号、引号、数字、null 等。在常规的(非引导式)生成过程中,我们只能寄希望于模型能正确学习并避免生成语法上不合规的 JSON。但在引导式生成中,采样器将 仅 从这些合法的 Token 中进行选择,忽略其它可能性更高的无效 Token。5
更棒的是,通过使用如 Outlines 或 jsonformer 等库,你可以为引导式生成的采样器提供一个模式 (schema),采样器将在这一模式内进行选择!例如,如果某个键需要一个数字,采样器将在该键名后只选择数字。注意,这个例子中返回的对象与 Pydantic 模式完全吻合:
...class Weapon(str, Enum):sword = "sword"axe = "axe"mace = "mace"spear = "spear"bow = "bow"crossbow = "crossbow"class Armor(str, Enum):leather = "leather"chainmail = "chainmail"plate = "plate"class Character(BaseModel):name: constr(max_length=10)age: intarmor: Armorweapon: Weaponstrength: intmodel = ...generator = outlines.generate.json(model, Character, max_tokens=100)print(generator("Give me a character description", rng=...))# {# "name": "clerame",# "age": 7,# "armor": "plate",# "weapon": "mace",# "strength": 4171# }
这对于确保生成结果的可靠性大有裨益,但它又是如何与提速相关的呢?我们不妨再次审视上面的响应。如果我们将其与所需的模式进行对比,我们会发现几乎没有哪个 Token 是含糊不清的——对于大多数回应内容而言,模型通常只有一个可能的 Token 可以选择。在这种情况下,采样器可以直接选择这个 Token,完全绕开整个模型的处理过程!只有少数部分 Token(用绿色高亮显示的那些)实际上需要模型进行前向处理:
{"name": "clerame", //(4 个含糊不清的 Token:cl er ame ",\n) "age": 7, // (2 个含糊不清的 Token:7 ,\n)"armor": "plate", // (1 个含糊不清的 Token:plate)"weapon": "mace", // (1 个含糊不清的 Token:m)"strength": 4171 // (3 个含糊不清的 Token:417 1 \n) }}
在 JSON 语法和模式之间,我们已经确定前 7 个 token 是 {\n "name": ",因此我们可以在第一次调用模型前,自动将它们加入到上下文中。接着,当模型生成了 clerame",\n 后,我们知道在模型实际需要生成年龄("age":)之前的下一个 token,所以我们再次调用模型前也会将它们添加进去,以生成 7,。这样的步骤可以持续进行下去。(我们甚至可以通过补全 m 为 "mace", 来节约一个 token,因为没有其他武器以 m 开头!)
整个回应共包含 41 个 token,但其中只有 11 个需要模型生成,其余的都是自动插入的,并且仅作为提示 token 处理,这大大加快了处理速度。这不仅加速了处理过程,而且提高了可靠性——实现了双赢。如果你需要使用大语言模型 (LLMs) 来生成结构化数据,特别是那些可以使用自定义采样器的开源大语言模型 (OSS LLMs),那么你肯定应该考虑使用像 Outlines 这样的库。
预见解码
预见解码 是一种新的推测性解码方法,不依赖于传统的草稿模型。不同的是,模型本身在两个分支上运作:一个是预见分支,它预测并延伸候选的 N-gram(即短序列的 N 个 token),另一个是验证分支,用于验证这些候选项。这里的预见分支与常规推测性解码中的草稿模型类似,而验证分支则扮演类似于甲骨文模型的角色。
但不同于常规推测性解码,这一过程不仅仅在一个模型中完成,而是在单一模型的一次调用中,通过使用特制的注意力掩码来实现:
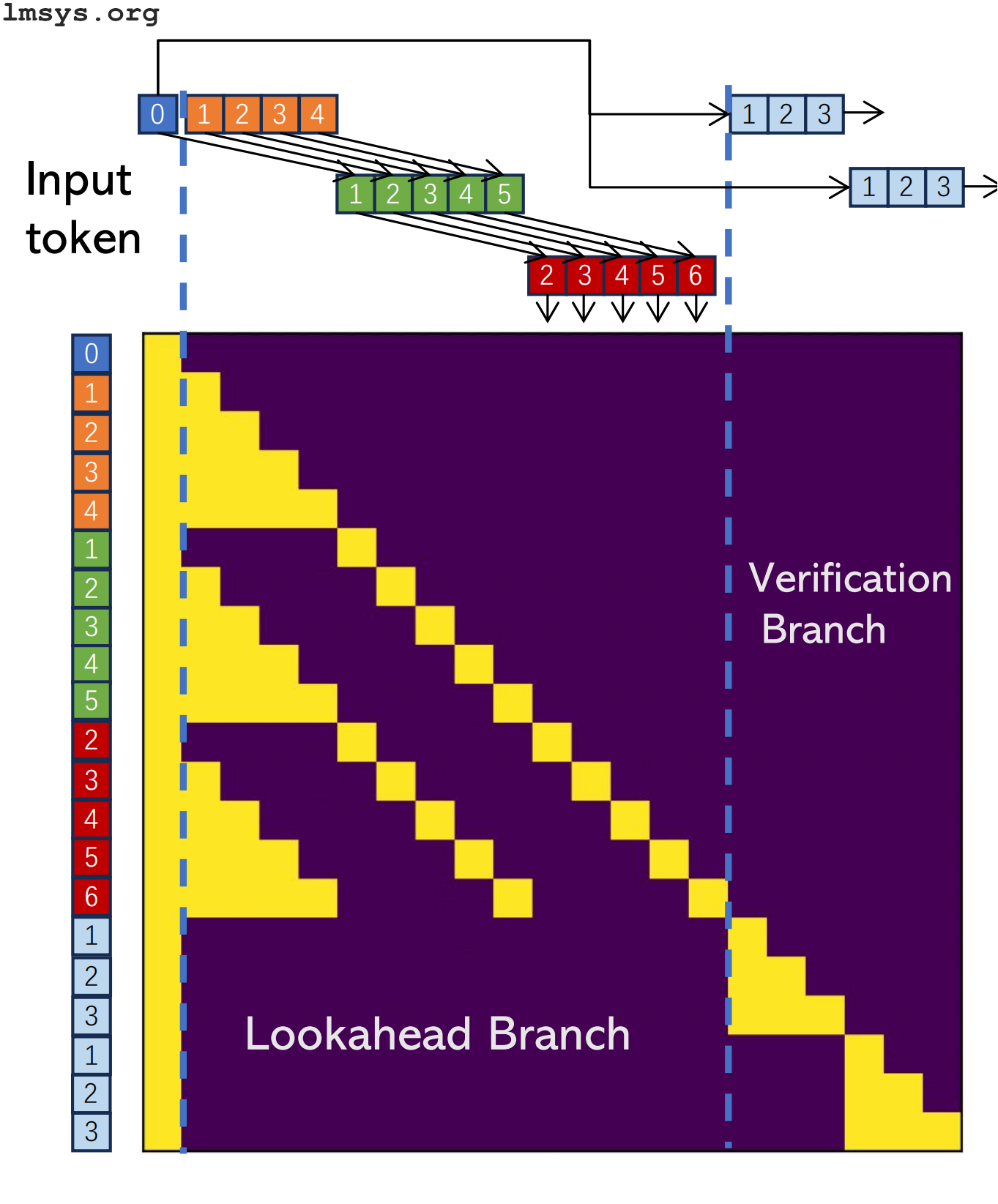
我不会深入探讨太多细节,因为 lmsys 博客文章 已经提供了一些很好的动画解释(尽管内容有些复杂)。
提示查询解码
提示查询解码 是一种新技术,它通过在上下文中进行简单的字符串匹配,来代替传统的草稿模型生成方法。研究人员发现,这种方法特别适用于代码编辑或 RAG(检索增强生成)等任务,因为这些任务的输出通常需要大量直接从输入中复制内容。我认为,在分阶段的推测性解码中,这种方法也可能有很好的表现,可以用来对初稿模型进行推测性解码。
训练期间的优化技巧
接下来介绍一些训练期间的优化技巧,我会简要说明,因为如果你没有资源从头开始使用这些技巧来预训练模型,它们可能不那么相关。
稀疏注意力机制
注意力机制在算法上之所以缓慢,是因为它的计算量随着序列长度呈二次方增长:序列中的每一个 Token 都需要与其他所有 Token 进行计算。稀疏注意力机制试图通过减少这种计算来改善性能。例如,Mistral 7B 使用了滑动窗口注意力机制,在某些层中,Token 只能关注其附近的 Token。Longformer 还探索了一些其他的稀疏注意力模式,如让所有 Token 访问特定位置,扩大滑动窗口,不同层使用不同大小的窗口等技巧。(虽然 Longformer 比 Mistral 更早出现,但据我所知,Mistral 并没有采用 Longformer 所有的技巧——具体原因不得而知。)
有时候,这种注意力机制可以在模型训练完后进行微调或直接添加,但要获得最佳性能,还是需要像 Mistral 那样,从一开始就将其训练进模型中。
非 Transformer 架构的新兴趋势
近期,非基于 Transformer 的大语言模型 (LLM) 再次成为研究热点。对于初入此领域的人来说,RNN/LSTM 可能不太熟悉,但在 Transformer 技术大放异彩之前,它们是处理序列数据的主流架构。RNN 与 Transformer 的不同之处在于,RNN 需要逐步扫描整个序列,通过构建隐藏状态来累积之前的信息,而 Transformer 则能够一次性处理整个上下文。(值得注意的是,还有反向和双向 RNN,这是该领域的一个重要分支。)
尽管 RNN 在可扩展性和遗忘问题上不如 Transformer,但近期的一些研究试图使其复兴,或是开发新的次二次方架构以挑战 Transformer 的主导地位。这些新架构包括 RWKV(一种新型 RNN)、Mamba(状态空间模型)、Hyena(卷积型),以及 Recurrent Memory Transformers(结合使用 Transformer 和特殊记忆 Token 来处理全局上下文)。虽然目前最先进的模型仍然是基于 Transformer 的,但这种局面在未来可能会发生改变。
结论
感谢您的阅读!
遗憾的是,由于篇幅所限,我没有能够涵盖所有我想要探讨的内容——比如我没有提及结构性稀疏化、混合专家系统、激活函数量化、静态与动态量化等许多其他重要主题。尽管如此,我认为这篇文章已经很好地概述了大语言模型 (Large Language Model) 优化的多个方面。目前大语言模型运行缓慢并且难以部署,但情况正在逐步改善——比如在我撰写这篇文章时,前瞻解码技术刚刚问世!看起来,在未来几年内,凭借更优秀的硬件、改进的训练方法、更精确的量化技术、更多的推理优化,加上开源社区的不懈努力,我们有望在消费级硬件上运行性能远超 GPT-4 的模型,而这些技术和更多的创新将是实现这一目标的关键。(当然,届时 GPT-5 可能已经发布了……但我们始终应向更高目标迈进!)
希望您觉得这篇文章有用且有趣。如果您喜欢它,也许您会对以下内容感兴趣:
- 我写的其他博客文章,比如《我如何手工制作一个 Transformer(无需训练!)》、《当 GPT-3 对工具意见不合时,它会选择忽略》、《GPT-4 是否在 JavaScript 中思考得更好?》以及《我对对抗训练数据的担忧》
- 我的其他项目和写作
- 我的 Twitter,我在那里分享新的博客文章、AI 相关的小想法(例如 1,2),我最近阅读的小说,以及其他有趣的内容。
如果您对这篇文章有任何想法,请随时联系我。我非常乐于听到读者的反馈。
致谢
首先,我要感谢所有参与这篇文章撰写和审阅工作的人:
- @wjessup (http://willjessup.com/) 对草稿进行了极其细致的审查。
- @tekknolagi (https://bernsteinbear.com/) 进行了审阅和提出了宝贵意见。
- @MF_FOOM 也参与了审阅和评论(还帮我租了一些 GPU 进行实验 🫡,虽然实验最终未能成功,可惜)
- Discord 上的 @laikhtewari 提供了很多精彩的主题建议。
- 在 Twitter 上点赞和评论我各种帖子的朋友们,你们的支持给了我极大的帮助。
1 在我的笔记本电脑(配置为 Intel i7-10510U (8) @ 4.900GHz, 48GB 内存)上,使用特定函数和 GPT-2-XL(拥有 15 亿参数)生成 50 个 token 的平均速度为每秒 0.22 token。相比之下,同样的提示下,通过实施如键值(KV)缓存和推测性解码等优化手段(未使用量化),我能够达到每秒 2.01 token 的生成速度,若使用量化处理,速度还有望进一步提升。
2 这篇博客 中提供了关于不同 GPU 模型的内存带宽和缓存大小的详细信息。值得注意的是,全局内存访问的速度大约是张量核心进行 4x4 矩阵运算的 380 倍!而 L1 缓存访问速度仅是后者的 34 倍,比全局内存访问快了约 10 倍。
3 虽然这种处理通常是手动完成的,但如果你使用 JAX,那么 jax.vmap 可以自动地批量处理一个原本只能操作单个样例的函数 🎉
4 那为什么不直接使用 MMU 而选择跳过 PagedAttention 呢?首先,MMU 要求内存分配必须按页面对齐,这可能与键值(KV)缓存条目的大小不成整数倍关系。更关键的是,我认为用户空间进程无法请求将一个虚拟页面映射到一个特定的物理页面,即便该物理页面已在进程中映射——这种权限通常是保留给内核的。如果有人知道这样做是可能的,请告诉我!
5 这正是 OpenAI 的 JSON 模式如何运作的。这也解释了为什么在给模型的提示中需要明确要求它以 JSON 格式回应。如果不这样做,词元(Token)的生成概率就不会与 JSON 格式相关联,结果可能导致模型陷入重复生成无意义空白的循环。